プロジェクト > 前翻訳
memoQwebで文書を前翻訳する時に、プロジェクト内の翻訳メモリ内とライブ文書資料のすべてのセグメントを検索し、最も一致するものを挿入します。一致するセグメントがない場合、memoQwebは、フラグメントからセグメントを結合するか、ソースセグメントから機械翻訳します。また、セグメントを自動的に結合または分割することもできます。
使用するマッチの品質を制御できます。
memoQwebは、正常に前翻訳されたセグメントを自動的に確定してロックします。
また、memoQwebは、前翻訳が開始される前のバージョンのドキュメントを保存できるため、前翻訳中に何が起きたかを確認し、必要に応じて前のバージョンに戻すことができます。
前翻訳後、memoQwebはドキュメントの分析を実行します。これにより、テキストがどの程度入力されたか、および一致の品質を確認できます。
注意:memoQ TMSが同じプロジェクトで自動タスクを実行している間は、オンラインプロジェクト内のドキュメントを前翻訳できない場合があります。この場合、数分待つように指示するメッセージが表示されます。これはエラーではありません:少し後で前翻訳を続行できます。
操作手順
- 管理者またはプロジェクトマネージャとしてmemoQwebにログインします。
- 有効プロジェクトリストでプロジェクトをクリックします。
- 画面の上部にあるTranslationsタブをクリックします。
- リストから1つまたは複数のドキュメントを選択します。
-
リストの上にある前翻訳リンクをクリックします。
前翻訳ページが開きます。
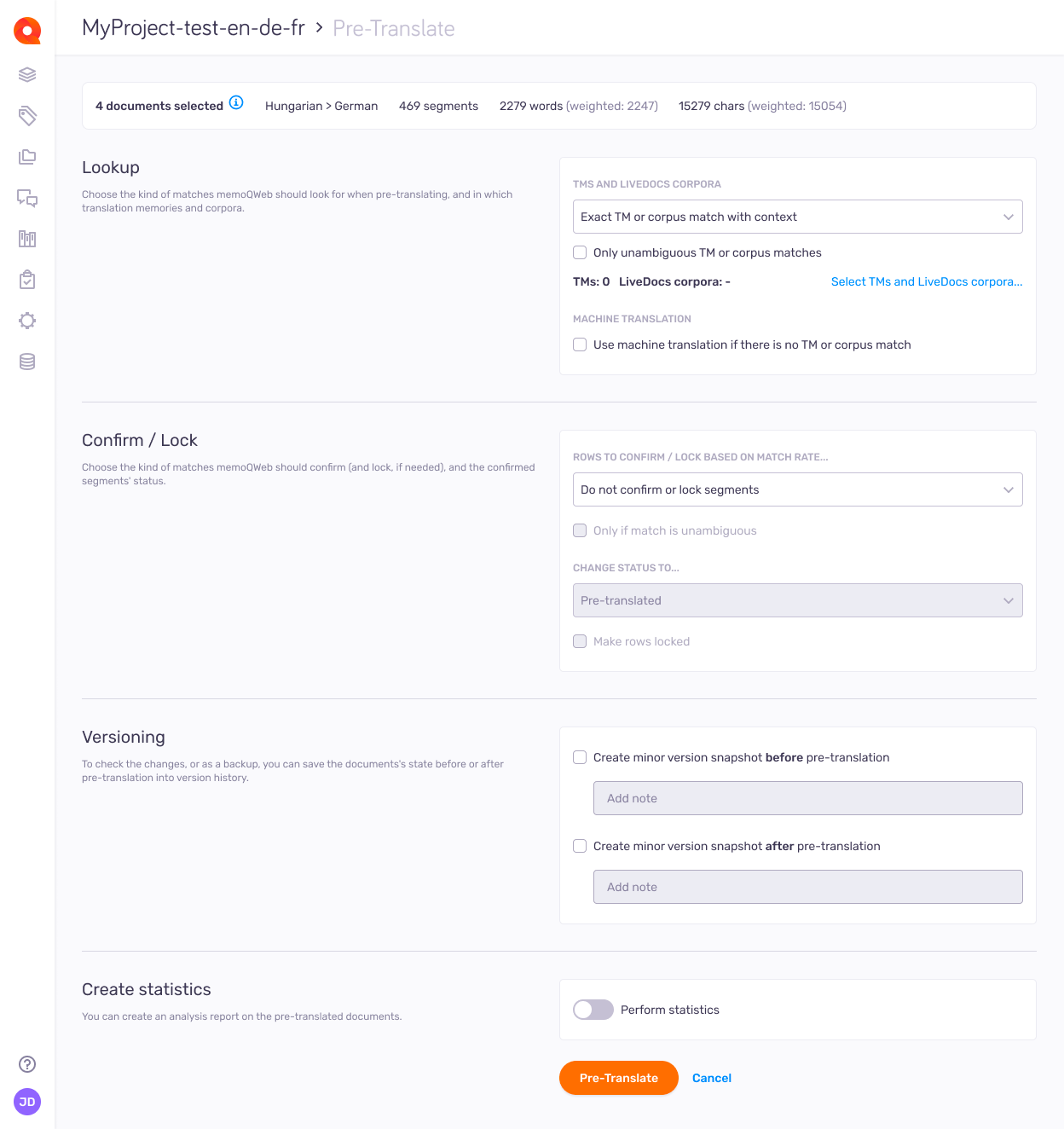
その他のオプション
ドキュメントの詳細を知る
上部の情報バーには次が表示されます:
- 選択したドキュメントの数。ドキュメント名を表示するには、青色の情報
 アイコンの上にマウスポインタを移動します。
アイコンの上にマウスポインタを移動します。 - プロジェクトのソース言語とターゲット言語
- ドキュメント内のセグメント数
- ドキュメント内の単語数 (元と加重値)。
- ドキュメント内の文字数 (元と加重値)。
memoQwebが挿入する一致を選択
ルックアップタブのTM およびライブ文書資料セクションの下にあるドロップダウンを使用します。
マッチ率が十分でない場合は、一致を挿入しないようにmemoQに指示することができます。
- TM または資料からのコンテキスト完全一致:コンテキスト (101%) またはダブルコンテキスト (102%) が一致する場合にのみ、セグメントを前翻訳します。
- TM または資料からの完全一致:完全一致 (100%) またはコンテキストマッチがある場合にのみ、セグメントを前翻訳します。
- TM または資料からの良好一致:「良好一致しきい値」を超える一致がある場合にのみ、セグメントを前翻訳します。これは翻訳メモリ設定で定義されます。この設定をチェックするには:
 アイコンをクリックし、プロジェクトでアクティブな翻訳メモリ設定プロファイルを編集します。
アイコンをクリックし、プロジェクトでアクティブな翻訳メモリ設定プロファイルを編集します。 - TM または資料からのすべての一致:一致がある場合は、マッチ率に関係なく、常にセグメントを前翻訳します。実際には、最小一致しきい値 (デフォルトで60%) を超えている必要があります。これを使用するには、翻訳メモリベースのセグメンテーションをオフにする必要があります (下記を参照)。
前翻訳に使用する翻訳メモリとライブ文書資料を選択する
プロセスを微調整するオプションは他にもあります:
-
高信頼度完全一致のみ:このチェックボックスをオンにすると、memoQwebは完全一致 (100%)、コンテキスト一致 (101%)、またはダブルコンテキスト一致 (102%) が1つだけの場合にのみ、セグメントが前翻訳されます。2つ以上ある場合、セグメントは前翻訳されません。
-
フラグメント結合を実行:翻訳メモリまたはライブ文書資料から一致するものがない場合、memoQwebはフラグメント結合一致を挿入できます。動作させるには、
含める一致で、用語、翻訳対象外項目、数値、自動翻訳ルールの結果、翻訳メモリおよびライブ文書資料からのフラグメントの置換を選択できます。通常、memoQwebはソーステキストの一部を置換するためにこれらのすべてを使用します。いずれかを使用しない場合は、これらの項目のチェックボックスをオフにします。
次に、フラグメント結合されたマッチがソーステキストからどれだけカバーするかを選択します。以下を提案のいずれかのラジオボタンを選択します。
- ヒットが 1 件のフル一致:フラグメントの結合一致は、1つの単一フラグメント一致でソースセグメント全体をカバーする必要があります。実際には、これによりフラグメントマッチングがオフになります。
- 複数のヒットでカバーされるフル一致:フラグメントの結合一致はソースセグメント全体をカバーする必要があります。つまり、ソースセグメントのすべての単語は、リソースからの何かによって置き換えられなければなりません。
- 次の値以上でマッチする一致(W):ソーステキストの一部のみを置換する必要があります。値を設定するには、ラジオボタンの横のボックスでパーセンテージを選択します。通常、memoQでは、ソーステキストの50%以上を置換できる場合、フラグメント一致が提供されます。
ソーステキストを含まないフラグメント結合された提案を作成できます。この場合、置換できないテキストは候補に含まれません。この場合は、一致が見つからない場合ソーステキストを削除チェックボックスをオンにします。
通常、memoQは、置換されるソーステキストに合わせて、単語の小文字/大文字の設定を調整します。これを停止するには、用語のケースを変更しないチェックボックスをオンにします。これをオンにすると、memoQは用語ベースから大文字/小文字の設定を保持します。
翻訳メモリベースのセグメンテーションや機械翻訳がオンになっていると、フラグメントの結合は動作しません。
-
TM 一致がない場合に機械翻訳を使用 (M):翻訳メモリまたはライブ文書資料から一致するものがない場合、memoQweb (legacy)はソースセグメントの機械翻訳を挿入できます。そのためには、プロジェクトのMT設定リソースで設定された機械翻訳サービスを使用します。動作させるには、
スイッチをオンにすると、各ターゲット言語の設定が表示されます。
言語のチェックボックスがオフの場合、memoQwebはその言語の機械翻訳を行いません。チェックボックスがオンにすると、ドロップダウンにプロジェクトのMT設定リソースで設定されているMTサービスが表示されます。1つを選択すると、memoQwebはその言語の前翻訳でそのMTサービスが使用されます。
翻訳メモリベースのセグメンテーションやフラグメントの結合がオンになっていると、機械翻訳は動作しません。
-
翻訳メモリベースのセグメンテーションの使用:memoQでは、セグメントの結合または分割を自動的に行うことができます。良好 (またはより良い) 一致のみを前翻訳する場合は、memoQweb (legacy)はセグメントを結合または分割して、その方法で完全一致が存在するかどうかを確認できます。これを行うには、
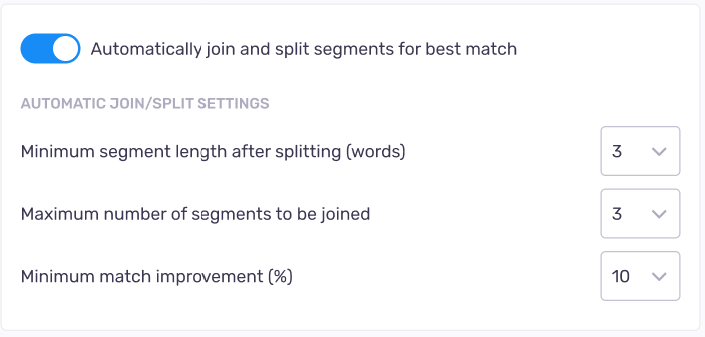
- セグメントの断片化の防止:通常、memoQweb (legacy)はセグメントから1つまたは2つの単語を分割しません。memoQweb (legacy)が分割できる単語数を設定するには:分割後の最小セグメント長 (単語数)設定を変更します。
- memoQが2つ以上のセグメントを結合できるようにする:より良い一致を得るために、memoQweb (legacy)は2つのセグメントを結合し、そこで停止します。文書があまりにも断片化されている場合は、memoQweb (legacy)はより多くのセグメントを結合できるようにすることができます。これを可能にするには、結合する最大セグメント数(J)で2より大きい値を設定します。
- memoQweb (legacy)が2つ以上のセグメントを結合できる場合:通常、10%マッチ以上マッチ率が向上すれば、もう1つのセグメントを結合します。この改善条件を変更するには、最小一致の改善 (%)設定を変更します。
機械翻訳やフラグメントの結合がオンになっていると、翻訳メモリベースのセグメンテーションは動作しません。
各言語で使用する
TMと資料:TM およびライブ文書資料を選択リンクをクリックします。前翻訳用の TM およびライブ文書資料を選択ウィンドウが開きます:
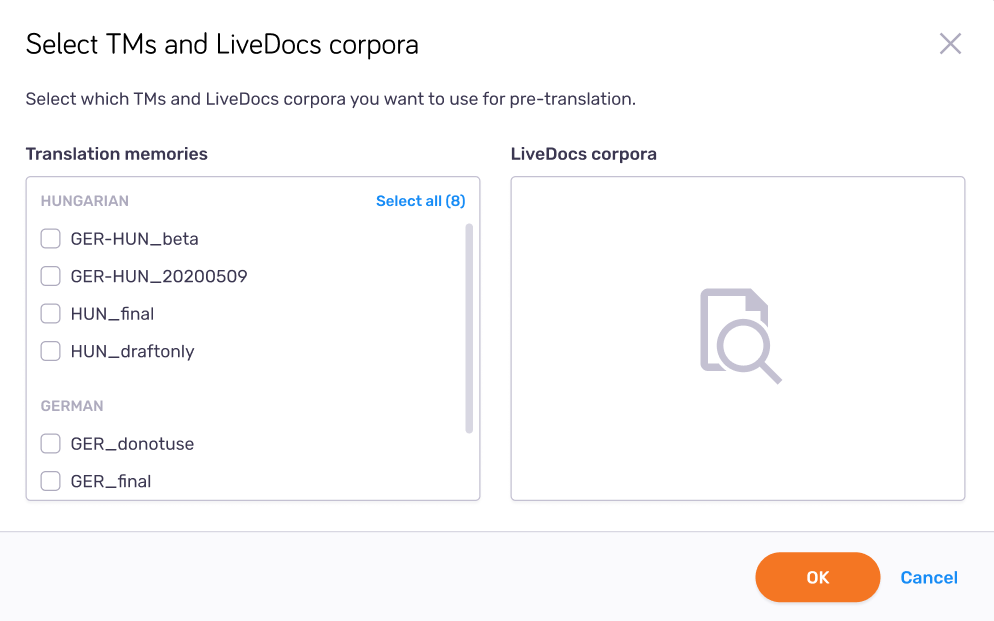
memoQweb (legacy)は、チェックボックスがオンになっているTMと資料を使用します。必要に応じて、各TMまたは資料のチェックボックスをオンまたはオフにします。すべてのTMまたは資料を選択または選択解除するには、すべて選択またはすべて選択解除リンクをクリックします。
変更を保存して
保存せずに
正常に前翻訳されたセグメントの確定とロック
memoQweb (legacy)は、前翻訳されたセグメントを自動的に確定またはロックできます。確定済みまたは校正済みセグメントのみが進行中の情報としてカウントされます。すべてのセグメントが確定済みまたは校正済みの場合にのみ、ドキュメントは100%完成です。他のユーザーが翻訳を変更させたくない場合は、これらの行をロックすることもできます。
ページの確定/ロックセクションでこれを行います。
まず、memoQweb (legacy)にどのセグメントを確定またはロックするかを指定します。マッチ率に基づいて行を確定/ロックのラジオボタンを使用します:
- セグメントを確定またはロックしない:前翻訳されたセグメントを確定しません。前翻訳状況のままです。
- 二重コンテキストの完全一致:ダブルコンテキスト (102%) 一致を確定またはロックします。
- コンテキストが完全一致:コンテキスト (101%) 一致を確定またはロックします。
- 完全一致:完全一致 (100%) 以上の一致を確定またはロックします。この設定には注意してください。コンテキストがないと、前翻訳に不適切な翻訳が挿入される可能性があります。
- 高信頼度完全一致の場合のみ:このチェックボックスをオンにすると、memoQweb (legacy)は、セグメントに対して2つ以上の完全一致またはそれ以上の一致がある場合、そのセグメントを確定またはロックしません。
次に、memoQweb (legacy)に検索している種類の一致を持つセグメントに何が起こるかを指定します。
- Pre-translated:セグメントのステータスを変更しません。
- Translator confirmed:セグメントを翻訳者確定済みとして確定します。
- Reviewer 1 confirmed:セグメントをレビュー担当者 1 確定済みとして確定します。
- Reviewer 2 confirmed:セグメントをレビュー担当者 2 確定済みとして確定します。
- 行をロック状態にする:このチェックボックスをオンにすると、memoQweb (legacy)は確定したセグメントもロックされます。
前翻訳の前と後のドキュメントの内容を保存する:新しいバージョンを作成する
memoQwebは、前翻訳の前後にドキュメントのスナップショットを作成できます。これにより、変更を確認したり、問題が発生した場合に以前のバージョンに戻すことができます。
通常、memoQwebは、前翻訳の前後のドキュメントのスナップショットは作成しません。

これを行うには、バージョン管理セクションの設定を使用します。
- 前翻訳の実行前にマイナーバージョンのスナップショットを作成:前翻訳の前に新しいマイナーバージョンを作成するには、このチェックボックスをオンにします。メモを追加することもお勧めします。
- 前翻訳の実行後にマイナーバージョンのスナップショットを作成:前翻訳の後に新しいマイナーバージョンを作成するには、このチェックボックスをオンにします。メモを追加することもお勧めします。
前翻訳後にドキュメントの分析を実行する
memoQweb (legacy)は、前翻訳と統計を一度に組み合わせることができます。動作させるには、
ここでは、前翻訳の分析レポートの実行方法を選択できます。
詳細については、分析レポートの作成に関するドキュメントを参照してください。あるいは、
一部のセグメントが編集済み、前翻訳済み、または確定済みの場合、前翻訳はどうなりますか?
一部のターゲットセグメントにすでにテキストが含まれている場合は、ある場合は前翻訳によってそれらのセグメントが上書きされ、その他の場合はそのままです。
- 一致がある場合、空 (開始前) セグメントは常に埋められます。
- memoQwebは以前に使用されたセグメントよりも良い一致がある場合、前翻訳セグメントは上書きされます。
- memoQwebは編集または確定されたセグメントは変更しません。これらのセグメントを上書きする必要がある場合は、最初に
完了したら
前翻訳を実行して翻訳ページに戻るには、前翻訳ボタンをクリックします。
ドキュメントを変更せずに翻訳ページに戻るには、キャンセル(C)リンクをクリックします。