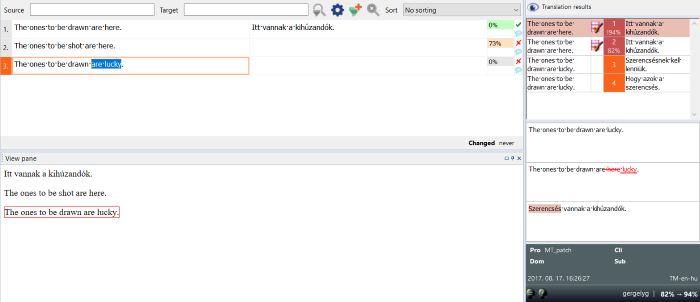
Translation results pane
As you translate, memoQ works in the background to help you. It pulls suggestions from various sources like translation memories, LiveDocs corpora, term bases, fragment matches, and auto-translation rules,
When you step on another row, memoQ starts querying the translation resources. The different types of resources are detailed in the sections below.
The Translation results pane has three parts:
The top part:
The top part of the Translation results pane shows a list of translation results (hits) coming from all translation resources.
- In the left column, you can see the source-language entry from the resource.
- The middle column shows an identifier number.
- The right column contains the target-language equivalent, if there is one.
If the list contains several results, you can move a highlight up and down in the list using the Ctrl+Up and Ctrl+Down keys.
Using the numeric keypad? You need to switch off NumLock for shortcuts with the Page Up, Page Down, Home, End, Up, or Down key.
The background color of each result indicates the resource it comes from:
Suggestions from translation memories or LiveDocs corpora are in red. memoQ compares the current source segment to those stored in the different translation memories added to the project.
The comparison algorithm uses letters and words, but not their meaning. Do not be surprised if some segments that memoQ finds similar actually have quite different meanings.
There are three types of "red" (TM-like) matches:
-
 - this match comes from a bilingual document in a LiveDocs corpus.
- this match comes from a bilingual document in a LiveDocs corpus. -
 - this match comes from an alignment pair in a LiveDocs corpus.
- this match comes from an alignment pair in a LiveDocs corpus. -
 - this match comes from a translation memory (TM).
- this match comes from a translation memory (TM).
If a match comes from a translation memory, you can edit the entry: Right-click the item in the Translation results list, and in the menu,
TM matches have a match rate in percent: This number shows the similarity between the source text in the match and the source text in the current segment.
When you receive a match from a translation memory or from a LiveDocs corpus, memoQ will score the match. The score shows how similar the current source segment is to the segment that memoQ found in the resource. You can receive a context match, an exact match, or a fuzzy match. Here is what each of them means:
-
Context match: In running text, the source segment is completely the same as in the resource. Plus, the previous and the next segment is the same (in the source text). In structured (XML) documents or tables, the source segment and its so-called context identifier is the same as in the resource. If the document has running text and context identifiers, and there is a match where both of them are the same, we call that a double-context match. The match rate for a simple context match is 101%. The match rate for the double-context match is 102%.
-
Exact match: The source segment is exactly the same in the document and in the resource, but the context is different. The match rate is 100%.
A TC (track changes) match is a special exact or context match: You see these when your source document contains tracked changes. You can use this if you have translated a document in the past, and now you need to translate an edited version of the same document. Because the changes are all marked, memoQ knows what the text was before the editing. memoQ will look up the text before editing - as if all changes were rejected - and return matches if there are any. A TC match is an exact match for the unedited version of the source segment.
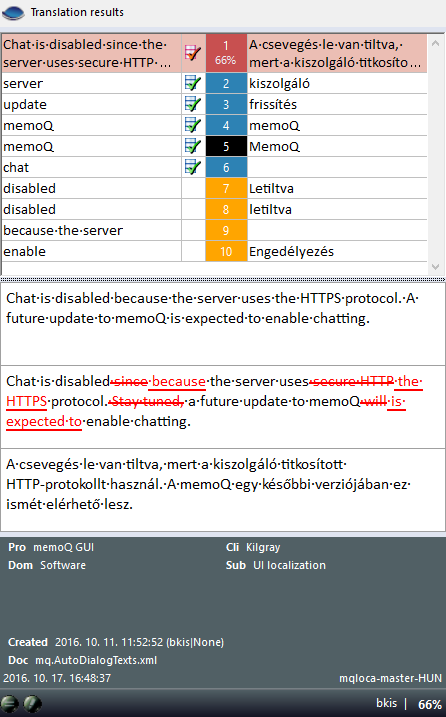
- High fuzzy match: The match rate is between 95% and 99%. The text is the same in the document and in the resource, but there are differences in the numbers, punctuation marks, tags, or spaces.
- Medium fuzzy match 1: The match rate is between 85% and 94%. In average-length segments (ca. 10 words), there is usually a difference of one word between the document and the resource.
- Medium fuzzy match 2: The match rate is between 75% and 84%. In average-length segments (ca. 10 words), there is usually a difference of two words between the document and the resource.
- Low fuzzy match: The match rate is between 50% and 74%. This difference is usually too much, and the match is not useful - except if the source segment is very short (less than 6 words). For short segments, fairly good matches can have low match rates.
memoQ shows lookup results coming from translation memories and LiveDocs corpora. When translating XLIFF:doc files, you might also see matches stored with translated rows. The order of translation results is the following:
Suggestions from term bases are blue. memoQ checks each word and phrase in the source cell, and offers a suggestion for each that is found in the project's term bases.
There are three types of "blue" (term base-like) matches:
-
 - The match comes from a regular term base. In many environments, this is considered the authoritative source.
- The match comes from a regular term base. In many environments, this is considered the authoritative source. -
 - The match comes from an accepted entry in a term extraction session.
- The match comes from an accepted entry in a term extraction session. -
 - The match comes from an external terminology service. To learn more, see section about the Terminology plugins pane of Options.
- The match comes from an external terminology service. To learn more, see section about the Terminology plugins pane of Options.
When you select a term base entry in the results list, the details of the entry appear below the list, in a formatted layout:
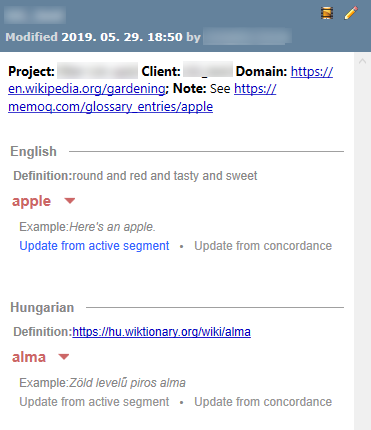
- Only the terms from the project languages are displayed, with the source language term on top, followed by the target term(s).
- Only the term selected in the Translation results list is expanded (both source and target), all other terms within the entry are collapsed.
To expand or collapse a term's information: On the right side of the term, click the triangle pointing downwards or to the right.
To edit a term base entry: ![]() icon in the upper-right corner. The Edit term base entry window opens.
icon in the upper-right corner. The Edit term base entry window opens.
To add the current segment to the term entry as an example: Under the language you want to update, click Update from active segment.
To add a concordance hit to the term entry as an example: Select a phrase in the translation editor, press Ctrl+K, select the concordance hit you want to add, and under the language you want to update, click Update from active segment.
To copy term information: Select entry-level (in the above image, Project and Client), language-level (Definition) and term-level (Example) metadata with your mouse. Press Ctrl+C. Or, right-click anywhere in this area, and choose Copy selection, Copy term pair info, or Copy entry info from the menu.
If the project you are working on has a Qterm term base, you can also add entries and edit existing entries in the Qterm term base (if you have the necessary permissions).
A match from a Qterm term base looks like this:
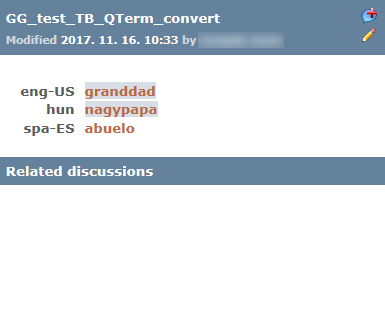

You can also start a discussion for a Qterm term base entry:
-
Click the Discussion
 icon: the Start a discussion dialog appears.
icon: the Start a discussion dialog appears. -
Enter a summary, a problem statement, and a suggested resolution, which start a discussion. If there are already discussions for the entry, they are listed below the terms, under Related discussions.
-
To contribute to a discussion: Click the heading of the discussion. The Topics window opens.
You cannot add a discussion or participate in one if the discussions are disabled on the server, in Qterm, or you are member of a group that is excluded from discussions.
You can also start a discussion for a Qterm term base entry. Click the Discussion ![]() icon: the Start a discussion dialog appears where you can enter a summary, a problem statement, and a suggested resolution, which start a discussion. If there are already discussions for the entry, they are listed below the terms, under Related discussions. To contribute to a discussion, click the heading of the discussion: that opens the Topics window.
icon: the Start a discussion dialog appears where you can enter a summary, a problem statement, and a suggested resolution, which start a discussion. If there are already discussions for the entry, they are listed below the terms, under Related discussions. To contribute to a discussion, click the heading of the discussion: that opens the Topics window.
Note: You cannot add a discussion or participate in one if the discussions are disabled on the server, in Qterm, or you are member of a group that is excluded from discussions.
When there are many term base hits: memoQ will order them, and even hide some, so that you get the most relevant list. By default, the hits appear as they come in the source text. If part of the source text is covered by more than one hits, the longer match will hide the shorter one (if you click the eye ![]() icon, the shorter ones will also appear). If there are several hits for the exact same source expression, the hits will be ranked by the priority of the term base and also their details: if two term base hits come from the same term base, but one of them has more in common with the project than the other, it will win. To learn more:
icon, the shorter ones will also appear). If there are several hits for the exact same source expression, the hits will be ranked by the priority of the term base and also their details: if two term base hits come from the same term base, but one of them has more in common with the project than the other, it will win. To learn more:
Fragment search suggestions are purple. memoQ attempts to put together the translation of the source segment from its smaller parts that are found either in the translation memories or the term bases in the project.
To learn more: See the topic about fragment assembly.
To turn fragment-assembled matches on or off: In the Options window, on the left, click Advanced lookup settings. There, click the Fragment assembly settings tab.
Automated concordance (or Longest Substring Concordance, LSC) suggestions are light orange. memoQ attempts to retrieve the longest possible expressions that can be found by concordancing, and tries to offer their equivalent too. If memoQ finds a translation, it appears on the list. You can insert this translation into the target cell just like TM matches.
If there is no translation: Double-clicking the suggestion will open the Concordance window, where you can find and insert the translation.
To turn automated concordance matches on or off: In the Options window, on the left, click Advanced lookup settings.
If at least one machine translation plugin is set up, and the Translation results setting is not turned Off on the Edit machine translation settings window's Settings tab, memoQ will ask a machine translation service for suggestions. These suggestions are deep orange. You can insert them into the target cell just like TM matches.
MT concordance suggestions (machine-translated versions of the phrase you selected) are yellow. You can insert these translations into the target cell like term base matches - they do not overwrite the content already there.
Non-translatable items appear in gray. These must not be translated. Using these suggestions, you can insert the exact same word or expression in the target cell.
Results from auto-translation rules are green. Auto-translation rules are patterns that memoQ looks for in the source segment. Some linguistic elements have many combinations, and cannot be listed, but can be described using special rules. These elements include dates, measures, currency conversion, etc.
The middle part:
When you select a LiveDocs match or a translation memory match in the Translation results pane, more details appear in three boxes just below the list.
These compare boxes show:
- first, the current source segment;
- second, the source text from the selected suggestion;
- third, the target text from the selected suggestion.
You can choose from two views. When you receive your first TM result, a notification appears:
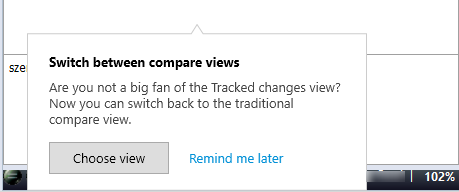
To make a choice later: Click Remind me later. memoQ keeps using the Track changes view. The same notification will appear later.
To make a choice now: Click Choose view. The Compare different views window opens (see below).
If you made a choice and want to change it:
-
Above the Translation results list, double-click the eye
 icon.
icon. -
In the Translation results settings window, under Compare boxes, select Track changes view or Traditional compare view.
OR:
-
In the top left corner of memoQ, on the Quick access toolbar, click the Options
 icon.
icon. -
On the left side of the Options window, click Miscellaneous in the list.
-
On the Lookup results tab, under Compare boxes, select Track changes view or Traditional compare view.
To see the difference: Click the Compare different views link.
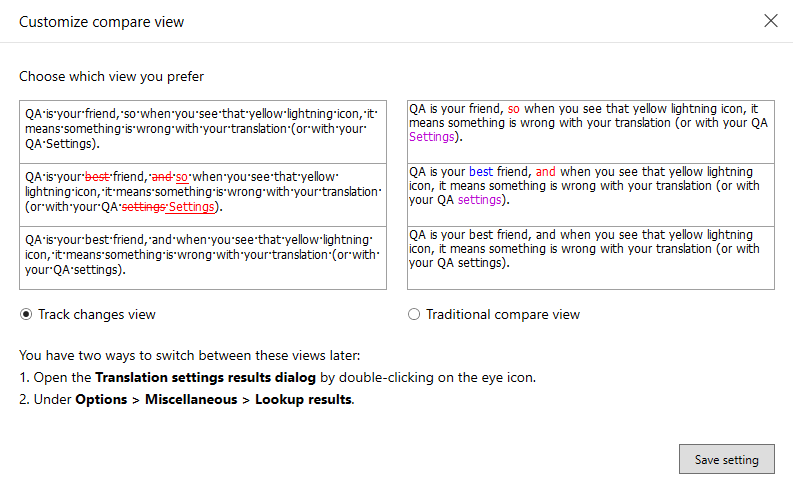
Track changes view:
The differences between the two source segments appear as tracked changes - the same way as tracked changes appear in the text.
The changes are highlighted in the second box only, as if the translation memory match were corrected into the current source segment. This means the following:
- New parts that are there in the current source segment appear as inserted;
- Old parts that appear in the match (only) appear as deleted.
Traditional compare view:
memoQ uses color codes to highlight differences between the translation result and the source text:
- Black: Identical parts in the source and the hit segment.
- Red: Differences between the first and second compare boxes. Examine the highlighted parts, and adjust the suggestion to the source text.
- Blue: A word is missing from the suggestion. Add it to the translation.
To change the color of the markups: Use the Compare boxes tab of the Options - Appearance pane to change the colors as needed.
To change fonts and font colors: Use the Translation grid tab of the Options - Appearance pane to change these colors and fonts. This article is about the normal settings; if you change them, this description may no longer fit your copy of memoQ.
The bottom part:
Below the three compare boxes, memoQ shows descriptive fields about the selected suggestion.
For translation memory entries, you get the following:
- Sub, or subject
- Dom, or domain
- Pro, or project identifier
- Cli, or the client the translation memory was created for
- The name of the translation memory or LiveDocs corpus where the entry comes from.
- The username of the person who created or last modified the entry.
- The date and time the entry was created or last modified.
- Match rate of the suggestion.
- The user role stored in the translation memory: Was this entry confirmed by a translator, a reviewer 1, or a reviewer 2?
There are two sets of little "lamps" at the bottom of the Translation results pane when a translation memory match is selected in the upper list:
![]()
The two lamps on the left indicate if the currently selected entry is a result of automatic alignment  , or if the source text segment in the translation editor was edited and re-sent to the translation memory
, or if the source text segment in the translation editor was edited and re-sent to the translation memory  . For instance, there is a typo in the source segment, you can right-click the segment entry, and choose Edit source. Correct the source of the entry, then click Ctrl+Enter to save your changes. This is the case, when you see the as indicator when you go back to this segment in the translation grid.
. For instance, there is a typo in the source segment, you can right-click the segment entry, and choose Edit source. Correct the source of the entry, then click Ctrl+Enter to save your changes. This is the case, when you see the as indicator when you go back to this segment in the translation grid.
The project manager can allow or forbid translators to edit source text.
There are six other icons that appear when the selected translation memory match has a rate of 95-101%. These icons, when lit up, indicate minor differences between the current source segment and the TM entry's source text (e.g. segment previously formatted bold, now formatted italic):
-
 - the current source cell has fewer or more space characters than the TM entry
- the current source cell has fewer or more space characters than the TM entry -
 - different punctuation
- different punctuation -
 - uppercase/lowercase is different
- uppercase/lowercase is different -
 - bold/italics/underline formatting is different
- bold/italics/underline formatting is different -
 - tags are different
- tags are different -
 - numbers and entities are different
- numbers and entities are different
If a lamp is lit up in color, then you need to fix that sort of difference manually. If it is lit up slightly, in gray, that tells you that memoQ detected that there is a difference, but also fixed it for you. For example, memoQ can apply bold formatting to the entire target segment or replace the numbers to match those in the source text, and so on.
For terms, you will see the same information except for the Aligned label and the entry's match rate.
For numbers and entity differences to light up, you need to change the default TM settings. From Project home, choose Settings, and click the TM Settings tab. Clone the default settings. Then click Edit, and clear the Adjust fuzzy hits checkbox. From this point on, memoQ will not adjust numbers, but light up this lamp.
More information
At the top of the Translation results pane, the closed eye  icon indicates some hidden suggestions from translation memories, LiveDocs corpora, and term bases. Normally, memoQ works like this.
icon indicates some hidden suggestions from translation memories, LiveDocs corpora, and term bases. Normally, memoQ works like this.
To get every suggestion, click this icon. Or, press Ctrl+Shift+D. It becomes an open eye:  .
.
To check (and choose) which suggestions are hidden, see the article about the Translation results settings window.
When you have a long source segment, and there is no match from the translation memories, memoQ can look for smaller parts of this segment in the translation memories and term bases assigned to the project. If there are shorter segments stored in the translation memories or the term bases (along with their translations), memoQ can attempt to look for smaller parts (fragments) of your long source segment, and insert their translations into the target segment. This is done automatically: when you move to a segment, and memoQ searches the translation memories and term bases, the “patchwork” matches, or fragment matches, if there are any, will automatically appear on the hit list.
Normally, the fragment matches appear on the hit list in purple. You can go to those by pressing Ctrl+Down. Then press Ctrl+Space to insert them. Alternatively, you can double-click the purple block of the hit on the list, or hold down Ctrl, and press the number (if there is one – the first 9 hits are numbered.).
Suppose you have translated the following segments earlier:

... and you have the following entry in your term base:
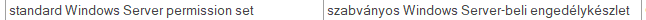
Then, you need to translate the following segment in another document:

To fill in the translation for the above segment, simply place the caret into the target segment. memoQ will automatically find the two smaller segments in the translation memory, and the term base entry for the term at the end of the segment. The assembled translation will automatically appear in the hit list:
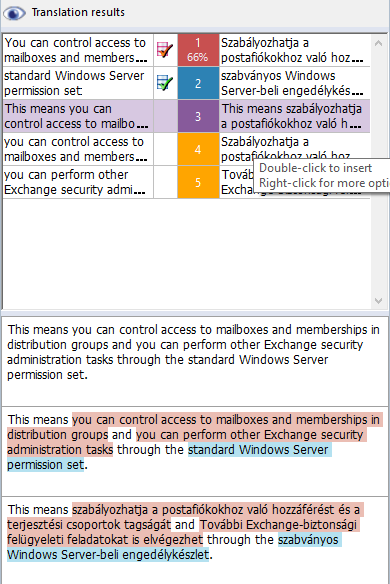
To insert the suggested translation, press Ctrl+3 – or, use Ctrl and the arrow keys to navigate to the suggestion, then press Ctrl+Space.
When memoQ attempts to put together a translation from fragments, it will always look for the longest possible fragment from the beginning of the segment. When a fragment is found, memoQ will look for the longest possible fragment again from the point where the previous fragment ended. If it does not find a fragment from the beginning of the segment (or the point it is searching from), it will attempt to look for a fragment from the beginning of the next word. If the subsequent searches are also unsuccessful, memoQ will move from one word to the next until a fragment is found or the end of the segment is reached.
In fragment searching, memoQ searches the translation memories and the term bases in the project. When searching translation memories, memoQ uses exact translation memory matches only. It does not attempt to find approximate (fuzzy) matches for the fragments in the translation memories. When searching term bases, memoQ does not use prefix matching.
When putting together a translation from fragments, memoQ will always cover the entire source segment. When looking for fragments, memoQ always goes word by word. If a word is not covered by a fragment match – that is, memoQ had to skip a word and continue searching from the next one –, the gap will be filled in by inserting that word in the source language. See the example above: some English text still remains in the suggestion. This is because memoQ did not find TM or TB entries that would cover those words.
Most of the time, fragment assembly will replace terms in the source text. When there are two or more term base hits for the same source-language words, memoQ has to choose one. For this reason, memoQ will score the term base hits, and the one with the highest score wins.
Of course, the longer hit is always stronger, but when the two or more hits are equally long, memoQ needs to look at them in more detail.
On the one hand, you can set up priorities between term bases - if a term comes from a more important term base, it will win.
On the other hand, If they come from the same term base, memoQ still needs a way to decide.
This process works if ranking is turned on. To turn on ranking, open the Translation results settings dialog, and select the Order term base hits primarily by rank and metadata checkbox.
Then memoQ will check how much a term base hit has in common with the project. If one term base hit has two details that match the project, and another has three, the hit that has three details will win.
If both term base hits have the same number of details that match the project, memoQ will check how important these details are. The order of importance, from most important to least important, is the following:
When memoQ finds a term in the text, it will appear on the list of suggestions. But in the example below, a translation memory match and a term base hit both come from the resources (that is, the translation memory and the term base), and memoQ will combine them:
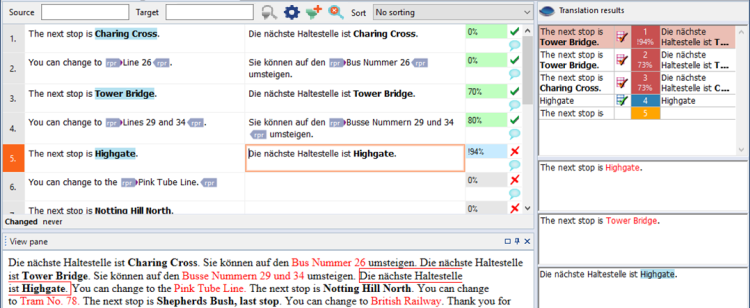
Note that memoQ inserted a translation that is absolutely perfect. How can this be if the translation memory match was ‘The next stop is Tower Bridge’?
The difference between the source text and the translation memory match was the name of the station: ‘Highgate’ in the source text, and ‘Tower Bridge’ in the translation. Both names were there in the term base, too. memoQ could find the translation of ‘Tower Bridge’ in the stored translation, and because it already knew how to translate ‘Highgate’, the old name could be easily replaced with the new one.
When this happens, we say that memoQ patches the translation. memoQ also gives a higher score to the patched translation, but marks it with an exclamation mark (! – see the blue status box next to the segment).
To make this work, open the Options window. Choose Miscellaneous. Click the Lookup results tab. Select the Patch fuzzy TM matches checkbox.
To learn more: See section about the Options window.
memoQ shows a patched match with an exclamation mark before the match rate: !93%. At the bottom of the Translation results pane, two match rates appear: 73%->93%. This means that the match was originally 73%, but memoQ managed to improve it to 93%.
memoQ also uses the formatting of the source cell. If your term is formatted in bold, the target term will also be inserted in bold.
memoQ looks up each difference in fuzzy matches. So, in theory, it can patch all of them - but in practice, usually 1 or 2 differences are patched. This happens because MatchPatch needs high match scores, and few hits in the reference materials are good enough. Patching with machine translation has some limitations, too:
-
memoQ looks up phrases in only one MT service, only once, and takes only the first returned translation. If that translation differs from the one in the translation memory's fuzzy match, memoQ cannot patch that phrase.
-
memoQ does not look up words with 3 or fewer letters.
You still need to adjust the ending or the word form, depending on your target language. In The Grid, patched matches are indicated with light blue, which is different from "normal" pre-translated segments.
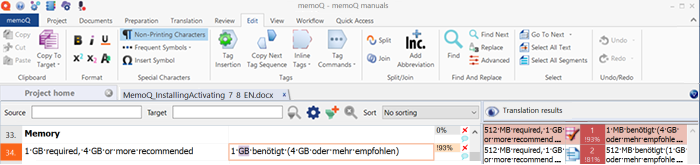
No patching while pre-translating: memoQ will not fix matches during pre-translation.
Does not patch numbers or tags: That is the task of the translation memory itself. MatchPatch works with text differences only.
Patched matches get a penalty: A patched match may be perfect (exact), but memoQ applies a penalty. The match rate of a patched fuzzy match never exceeds 94%.
Example 1:
English source text:Chocolate was the best-selling commodity in the last summer.
Resources:
The above sentence was stored in your TM with the proper German translation: Schokolade war die meist verkaufteste Ware im letzten Sommer.
Your term base contains the term: ice cream = Eiscreme
Now you receive a source text that contains the English:
Ice cream was the best-selling commodity in the last summer.
German target:Eiscreme war die meist verkaufte Ware im letzten Sommer.
Example 2:
English source text: Chocolate was the best-selling commodity in the last hot summer.
Resources:
The above sentence was stored in your TM with the proper German translation: Schokolade war die meist verkaufte Ware im letzten heißen Sommer.
Your term base contains the term: ice cream = Eiscreme and cold = kalten
Now you receive a source text that contains the English:
Ice cream was the best-selling commodity in the last cold summer.
German target:Eiscreme war die meist verkaufte Ware im letzten kalten Sommer.
If you have access to a machine translation service, you can also use it to patch fuzzy matches coming from the TMs.
- Open the Edit machine translation settings window.
- If necessary, click the MT service's row in the list and configure the plugin.
- On the Settings tab, choose a service from the MatchPatch dropdown.
- Click OK.
If MatchPatch cannot patch a fuzzy match using term base or TM results, it will use the selected MT service for patching.