Propriétés de la mémoire de traduction
Dans la fenêtre des propriétés de la mémoire de traduction, vous pouvez changer le nom et les détails descriptifs de la mémoire de traduction, la rendre en lecture seule, enregistrer les noms de document dans de nouvelles entrées (ou arrêter de les enregistrer). Vous pouvez également vérifier le nombre d’entrées ou le chemin d’accès où se trouvent les fichiers de la mémoire de traduction. De plus, vous pouvez ajouter, supprimer ou modifier des champs personnalisés.
Vous ne pouvez pas changer ici les langues de la mémoire de traduction ni la façon dont elle stocke le contexte.
Comment se rendre ici
-
Dans Accueil, choisissez Mémoires de traduction

OU
D’un projet en ligne: En tant que chef de projet, vous pouvez ouvrir un projet en ligne pour la gestion. Dans la fenêtre du projet en ligne memoQ, choisissez les mémoires de traduction
.OU
Ouvrez la Console de gestion des ressources
 , et choisissez les mémoires de traduction
, et choisissez les mémoires de traduction .
. -
Faites un clic droit sur le nom de la mémoire de traduction que vous devez modifier. Dans le menu, choisissez Propriétés.
-
La fenêtre Propriétés de la mémoire de traduction s’ouvre.
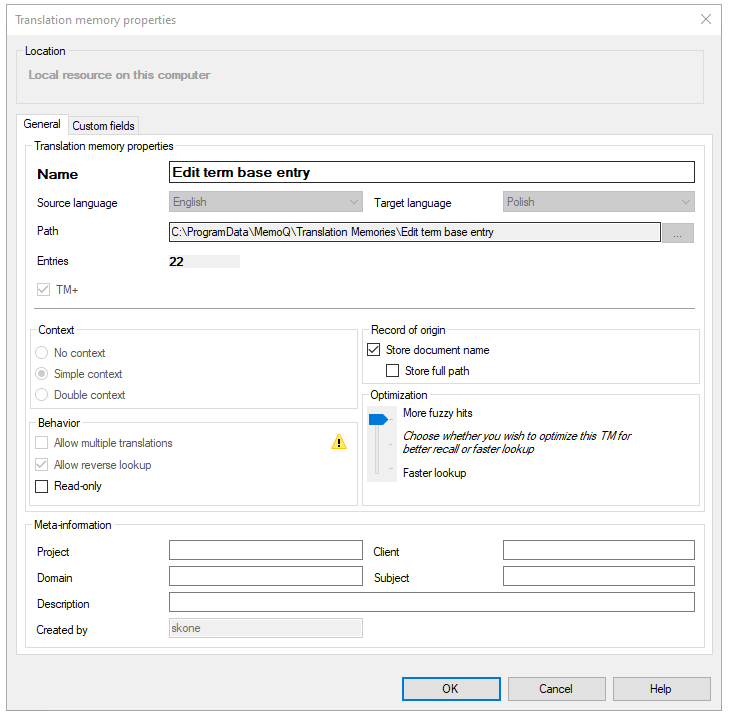
Si vous ouvrez la fenêtre Propriétés de la mémoire de traduction depuis l’éditeur de mémoires de traduction, elle est en lecture seule et ne peut pas modifier les valeurs.
Que pouvez-vous faire?
Sous les propriétés de la mémoire de traduction, modifiez le nom dans la boîte Nom. Le nouveau nom doit être unique sur votre ordinateur - ou sur le serveur où vous le créez.
-
Vérifiez les langues dans les cases de la langue source et de la langue cible.
-
Vérifiez le dossier de la mémoire de traduction dans la zone Chemin d ’accès.
Pour ouvrir le dossier dans Windows: Sélectionnez le contenu de la zone Chemin d’accès, et copiez-le dans le Presse-papiers en appuyant sur Ctrl+ C. Appuyez sur la touche Windows, et collez le chemin d’accès en appuyant sur Ctrl+ V. Appuyez sur Entrée. Le dossier s’ouvre dans une fenêtre de dossier Windows.
-
Vérifiez le nombre d’entrées dans la mémoire de traduction dans la case Entries.
Pour voir si une nouvelle mémoire de traduction est un MT+: Sous les propriétés de la mémoire de traduction, regardez la case MT+.
Dans un MT+, vous pouvez soit:
-
Enregistrer Contexte- La mémoire de traduction vous donnera une correspondance en contexte si le segment et son contexte sont les mêmes dans la mémoire de traduction. Pour retourner des correspondances en contexte, une mémoire de traduction doit stocker le contexte.
OU
-
Autoriser les traductions multiples - Cette option n’est pas recommandée, à moins que vous importiez une mémoire de traduction d’un autre outil de traduction, et qu’il y ait plusieurs traductions dans le fichier que vous importez. Lorsque deux traductions sont différentes, dans la plupart des cas, le contexte est également différent. Si vous utilisez le contexte dans une mémoire de traduction, il n’y a pas d’utilité pour plusieurs traductions.
Vous ne pouvez pas changer la façon dont la mémoire de traduction gère le contexte, mais vous pouvez vous renseigner sur la configuration.
La mémoire de traduction vous donnera une correspondance en contexte si le segment et son contexte sont les mêmes dans la mémoire de traduction. Pour retourner des correspondances en contexte, une mémoire de traduction doit stocker le contexte.
Par exemple, si vous devez reconstruire la traduction d’un document à partir d’une mémoire de traduction, vous avez besoin des correspondances en contexte. Ils sont également utiles si vous devez mettre à jour la traduction pour une nouvelle version du document source, et qu’il y a peu de différences entre les deux versions.
memoQ a deux types de correspondances en contexte:
Correspondance simple en contexte: Correspondances exactes en contexte pourcentage de correspondance
- Contexte du flux de texte - lorsque le document source contient du texte en cours d’exécution, le contexte est le segment précédent et le segment suivant.
- Contexte basé sur l’ID - lorsque le document source est une table ou un document structuré où chaque entrée a, ou peut avoir, un identifiant. Dans ce cas, le contexte est l’identifiant, et memoQ renvoie une correspondance en contexte si le segment et l’identifiant sont identiques dans la mémoire de traduction.
Correspondance en contexte double: Correspondance à 102% pourcentage de correspondance
-
Un contexte double est possible dans des documents qui contiennent à la fois du texte en cours d’exécution et des identifiants. Dans ce cas, memoQ peut vérifier à la fois dans la mémoire de traduction.
Pour en savoir plus sur le pourcentage de correspondance: Lisez le sujet sur les pourcentages de correspondance des mémoires de traduction et des bases LiveDocs.
Mémoire de traduction sans contexte:
Vous pouvez également créer une mémoire de traduction qui ne stocke aucun contexte. Ceci n’est pas recommandé à moins que vous ne prévoyiez d’utiliser la mémoire de traduction uniquement à titre de référence et d’importer des fichiers de mémoire de traduction d’un autre outil de traduction. Si une mémoire de traduction ne stocke aucun contexte, ne la faites pas devenir la mémoire de traduction de travail ou la mémoire de traduction ultime dans un projet. Lorsque vous confirmez des segments, memoQ essaiera toujours de sauvegarder le contexte. Si vous confirmez des segments dans une mémoire de traduction sans contexte, vous perdrez des données.
Vous ne pouvez pas changer ce paramètre après que la mémoire de traduction a été créée.
Ne pas utiliser plusieurs traductions: memoQ peut stocker plusieurs traductions pour le même segment source. Cette option n’est pas recommandée, à moins que vous importiez une mémoire de traduction d’un autre outil de traduction, et qu’il y ait plusieurs traductions dans le fichier que vous importez. Lorsque deux traductions sont différentes, dans la plupart des cas, le contexte est également différent. Si vous utilisez le contexte dans une mémoire de traduction, il n’y a pas d’utilité pour plusieurs traductions. Assurez-vous que la case Autoriser les traductions multiples est décochée.
Lorsque vous confirmez un segment dans l’éditeur de traduction, memoQ enregistrera le nom du document ainsi que le segment et sa traduction. Cela peut être intéressant lorsque vous révisez des traductions - ou que vous devez décider de quel degré de confiance accorder à la traduction.
Si vous ne voulez pas que les noms de document figurent dans la mémoire de traduction: Décochez la case du nom du document du magasin.
Vous pouvez le rallumer. Pour ce faire, ouvrez la fenêtre Propriétés de la mémoire de traduction.
Protéger la mémoire de traduction contre les modifications accidentelles: Cochez la case Lecture seule. memoQ ne permettra à personne d’y apporter des modifications - jusqu’à ce que vous décochiez la case en lecture seule dans la fenêtre Propriétés de la mémoire de traduction.
Faites cela dans l’onglet champs personnalisés.
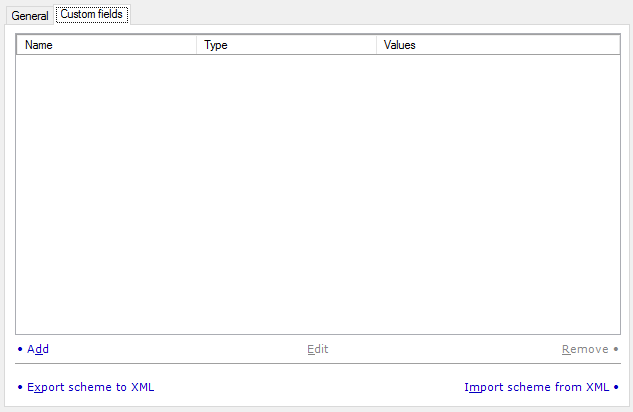
Vous pouvez ajouter des champs personnalisés à la nouvelle mémoire de traduction. Chaque unité de traduction peut avoir des métadonnées dans les champs standards (qui existent dans chaque mémoire de traduction) et les champs personnalisés (que vous ajoutez ici). Chaque mémoire de traduction peut avoir différents champs personnalisés.
20 champs personnalisés maximum : Une mémoire de traduction ne peut contenir plus de 20 champs personnalisés.
Cette liste contiendra déjà certains champs personnalisés si:
- Les champs personnalisés sont déjà définis dans l’onglet Schéma MT par défaut de la catégorie Divers dans la fenêtre Options, ou
- vous êtes arrivé ici en clonant une mémoire de traduction (dans la Console de gestion des ressources ou le volet Mémoires de traduction de l’Accueil) qui a des champs personnalisés.
Les options suivantes sont disponibles :
- Ajouter: Cliquez sur ce lien pour ajouter un nouveau champ personnalisé au schéma MT par défaut. La fenêtre Propriétés des champs personnalisés s’ouvre. Précisez le nom et le type du nouveau champ personnalisé. Si vous choisissez Picklist (single) ou Picklist (multiple) comme type, vous devez énumérer les valeurs possibles pour le champ.
- Éditer: Cliquez sur ce lien pour changer le type du champ personnalisé sélectionné. La fenêtre Propriétés des champs personnalisés s’ouvre. Vous ne pouvez pas changer le nom: la boîte Nom sera grisée. Vous pouvez changer le type du champ. Si vous choisissez Picklist (single) ou Picklist (multiple) comme type, vous devez énumérer les valeurs possibles pour le champ.
- Supprimer: Cliquez sur ce lien pour supprimer le champ personnalisé sélectionné de la liste. Cela ne fonctionne que avant de cliquer sur le bouton OK.
- Exporter structure vers XML: Cliquez sur ce lien pour exporter la liste des champs personnalisés dans un fichier XML qui peut être utilisé lors de la création de nouvelles mémoires de traduction, tant sur cet ordinateur que sur d’autres ordinateurs exécutant memoQ.
- Importer la structure à partir de XML: Cliquez sur ce lien pour remplir la liste des champs personnalisés qui ont été enregistrés dans un fichier XML précédemment à partir d’une autre copie de memoQ.
Il n’est pas possible de modifier ou de supprimer des champs personnalisés après l’enregistrement de la MT: Lorsque vous cliquez sur OK, memoQ enregistre les champs personnalisés dans la mémoire de traduction. Après cela, vous ne pouvez changer que les valeurs de la liste de sélection. Pour supprimer un champ personnalisé après l’enregistrement: Assurez-vous qu’aucune unité de traduction n’utilise ce champ. Exporter la mémoire de traduction dans un fichier TMX. Créer une nouvelle mémoire de traduction. Importer le fichier TMX dans la nouvelle MT - le champ personnalisé non désiré ne sera pas présent.
Lorsque vous avez terminé
Pour enregistrer les modifications dans la mémoire de traduction: Cliquez sur OK.
Pour revenir à la Console de gestion des ressources ou à l’Accueil sans enregistrer les modifications: Cliquez sur Annuler.