Statistics
Statistics in memoQ helps you estimate workload and billing by analyzing word counts, segment matches, and repetitions using your translation memories. This guide explains how to run and interpret statistics for different project roles and scenarios.
In the Statistics window, you can check how many words, segments, or characters are in your project or selected documents. memoQ also compares them with your translation memories and LiveDocs corpora to show how much content has already been translated or can be reused.
-
You can automate this: in a project created from a project template, memoQ can create an analysis report automatically.
-
Use the Statistics window when you need more settings: in a local project's overview or in an online project's Reports pane, you can quickly create analysis reports on the entire project, with fewer settings.
-
To find out how much work is needed, considering matches in your translation memories and LiveDocs corpora.
-
To analyze both local and online projects with tailored settings.
-
To estimate your billing based on weighted word counts.
memoQ groups words by match categories (100% match, 95-99%, etc.). Each category has a weight representing how much work is needed (0% = no work, 100% = full translation).
For example: A 90% match segment with 10 words and 50% weight counts as 5 words of work.
How to get here
-
Or create a project and import documents.
-
Open a document for translation - if you want to analyze part of it.
-
In the Documents ribbon, click Statistics.
-
The Statistics window opens.
You can manage online projects only if you're a member of the Project managers or Administrators group on the memoQ TMS – or if you have the Project manager role in the project.
-
In the memoQ online project window click Translations.
-
On the Preparation ribbon, click Statistics.
The Statistics window opens.
What can you do?
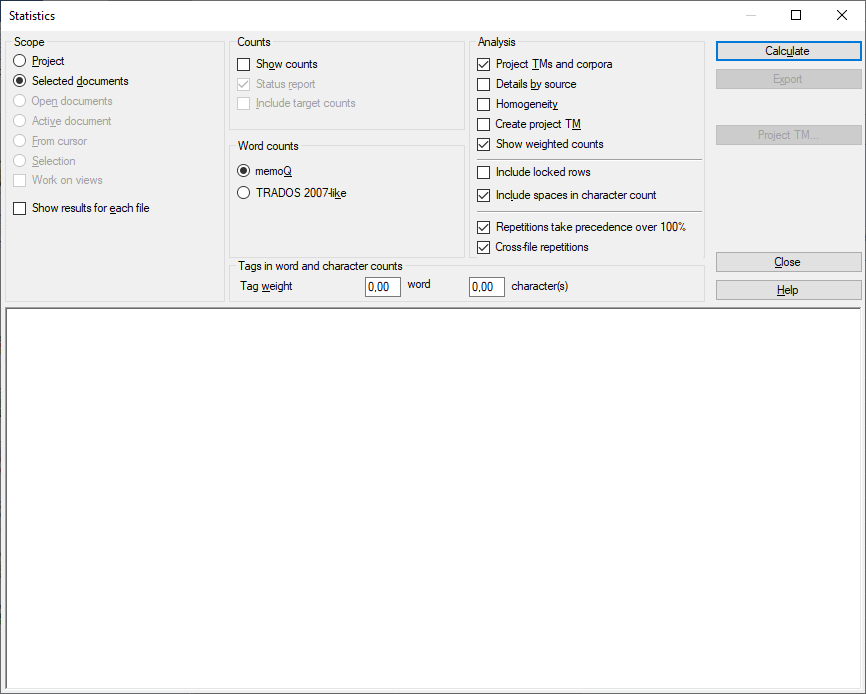
A scope tells memoQ which documents to look at.
-
Project: All segments in all documents of the current project. If the project has two or more target languages, memoQ checks segments in every target language.
-
Active document: All segments in the active document. You can choose this only if you are working on a document in the translation editor.
-
Selected documents: All segments in the selected documents. You can choose this only if you select several documents in Translations under Project home.
-
From cursor: Segments below the current position in the active document. You can choose this only if you are working on a document in the translation editor.
-
Open documents: All segments in every document that is open in a translation editor tab.
-
Selection: Selected segments in the active document. You can choose this only if you are working on a document in the translation editor.
-
Work on views: Segments in the views in the current project. You can choose this only if there is at least one view in the project.
Want to analyze segments in just one target language? Before opening the Statistics window, choose a language on the Translations pane. Select all documents, then open Statistics, and choose Selected documents.
These settings are for a local project.
When you run statistics on your own, use these settings in the Create analysis report window:
-
Use Project TMs and corpora to find matches. memoQ checks the segments in every translation memory and LiveDocs corpus in your project.
-
Use Homogeneity to count repeated segments correctly. memoQ predicts what matches you will get during translation while your translation memory is filled up. It makes sense to use this option only if you're working on the translation alone.
-
Clear the Include locked rows if there are any (these are segments you shouldn’t translate).
-
Choose Repetitions take precedence over 100% so repeated segments aren’t double counted. Use it only if a consistent translation is more important than using all possible matches from the translation memory.
-
Make sure to use Cross-file repetitions if your project has multiple documents, so repetitions across files are recognized.
-
Select Show weighted counts to see the real effort estimate.
Managing an online project?
If you are running Statistics on an online project, memoQ uses the weights from the memoQ TMS.
To set up weights on a memoQ TMS, use the Server Administrator. Choose Weighted counts, and check or set the weights.
These settings are for an online project. You can use them in a local project if you are a project manager, and you plan to publish the project on a server, or to distribute the project using packages.
If several translators will work on the project, use these settings in the Create analysis report window:
-
Use Project TMs and corpora to find matches. memoQ checks the segments in every translation memory and LiveDocs corpus in the project.
-
Don't calculate Homogeneity. You can't predict internal fuzzy matches because your don't know who translates a segment first.
-
Don't select Include locked rows unless translators will work on locked content.
-
Choose Repetitions take precedence over 100% so repeated segments aren’t double counted. Use it only if a consistent translation is more important than using all possible matches from the translation memory.
-
Clear Cross-file repetitions because we don't know who will translate a segment first - and they should get full compensation for translating.
-
Select Show weighted counts to see realistic work estimates.
To find out how much the work a team of translators did, use Post-translation analysis after the translation is finished.
If you are running Statistics on an online project, memoQ will use the weights from the memoQ TMS.
To set up weights on a memoQ TMS, use the Server Administrator. Choose Weighted counts, and check or set the weights.
To get a simple count of the whole text size without match analysis:
-
Clear the Project TMs and corpora, Homogeneity, and Cross-file repetitions checkboxes.
-
Select Include locked rows and Repetitions take precedence over 100%.
Editors (proofreaders) work on already translated content, regardless of matches, so it makes no sense to analyze the work through translation memories.
-
Clear the Project TMs and corpora, Homogeneity, and Cross-file repetitions checkboxes.
-
Check Repetitions take precedence over 100%, and if the editor reviews locked content, check Include locked rows.
Some markets measure translation volume by characters instead of words. memoQ always shows character counts alongside word counts.
To count spaces, make sure that Include spaces in character counts is selected. memoQ counts every space separately, for example, two spaces right after each other count as two, not one.
Formats like XML, HTML, PDF, InDesign, or Microsoft Word often include many inline tags, which add editing complexity. The analysis report must reflect that.
You can assign weights to tags:
-
Set tag weight in words or characters
In the Tag weight field, type a number in the word(s) or character(s) box (e.g., 0.25 words per tag or 2 characters per tag).
If you type 0.25, memoQ counts one word after every four inline tags, or, if you type 2, memoQ counts two characters after every tag.
-
memoQ then adds these weighted counts to your total workload estimate.
In the Statistics window, there are several options that tell memoQ what details to include in the report.
-
Show results for each file generates a report separately for each document.
-
Show counts shows total count for segments, words, and characters.
-
Status report shows segment statuses (confirmed, edited, pre-translated, not started).
-
Include target counts is needed if you bill based on target text size.
After setting your options, click Calculate. The process may take several minutes depending on project size.
When the analysis is finished, memoQ shows it at the bottom of the Statistics window:
You can review it here or export reports in multiple formats.
To export and save the analysis report:
-
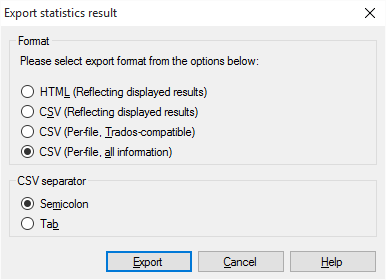
Click Export. The Export statistics result window opens.
-
Choose one of the formats:
- HTML (Reflecting displayed results): Saves the displayed statistics as HTML file.
- CSV (Reflecting displayed results): Save the results in a CSV file (to be opened in Excel).
- CSV (Per-file, TRADOS-compatible): Saves the results in a CSV file, where the details of each document occupy exactly one row. This is the old Trados style.
- CSV (Per-file, All information): Save the results in a CSV file, where the results are laid out exactly as in the Statistics window.
-
If you choose one of the CSV formats, you can choose the separator character that memoQ uses to delimit the columns in the table. There is no reason to use anything but the tab character: Under CSV separator, click Tab.
-
Click Export. A Save As window opens. Find a folder and a name for the report file, and click Save. memoQ exports the report, and returns to the Statistics window.
memoQ can collect all segments from the translation memories and the LiveDocs corpora found during analysis into a special Project TM for easier reuse.
To do that:
-
Before running the analysis, select the Create Project TM checkbox.
-
Run the analysis: Click Calculate.
-
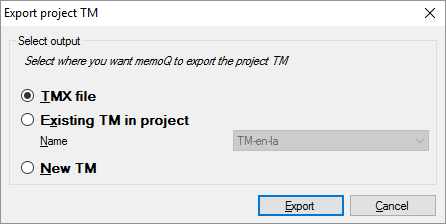
Save the translation memory: Click Project TM. The Export Project TM window opens:
-
Choose where memoQ should put the segments:
- You can save them in a TMX file, so that it can be imported on another computer, into a different translation tool.
- You can save them in a translation memory that is already in your project. From the Name drop-down box, choose the translation memory.
- Or, you can create a new translation memory in the project, and save the segments there.
-
Click Export. memoQ saves the segments.
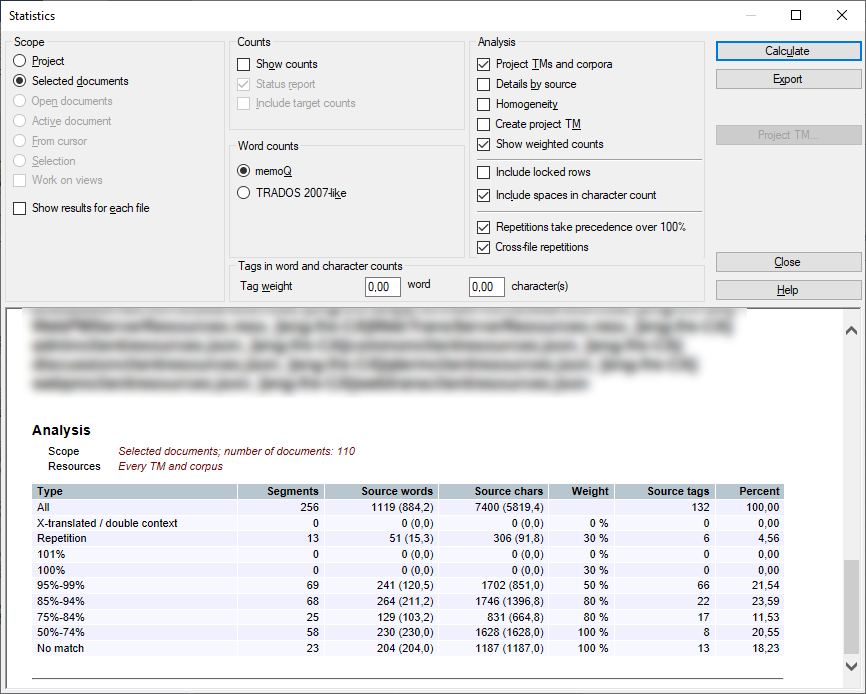
Results are split into two main sections:
-
Counts — shows total segments, words, characters.
-
Analysis — detailed breakdown by match type and resource (TMs, homogeneity, etc.).
You can have more than one Analysis section. It depends on the number of translation memories in your project, and the settings in the Show results for each file or the Details by source checkboxes.
Scope - shows the scope of the analysis selected in the Select scope section.
Resources - the resources against which the results were gained. Here you find the name of a translation memory or Homogeneity for homogeneity checks. If these are aggregate results, you see the caption Every TM and corpus or Every TM and corpus, Homogeneity.
You’ll see rows for:
-
All - entire scope (all source segments, source words, characters, and the source word count-based percentage).
-
X-translated - translated source segments, source words, characters, and the source word count based percentage.
-
Repetition- repeated segments (all source segments, source words, characters, and the source word count-based percentage).
-
Match ranges by percentage (e.g., 95-99%).
-
Segment counts, source and target word and character counts.
Analysis works for the selected scope. For example, if you have two documents in your project, and both contain the same segment only once, the statistics calculated for the project scope will show one segment as repetition. If you calculate statistics separately for the two documents, the results will not show any repetitions.
This difference may be significant if you plan to split a large project between different translators, because the overall statistics for the complete project may show a much higher rate of repetitions than the different sets of documents.
-
Not started: Number of untouched source segments, source words, characters and the percentage of the text counted from the word count.
-
Pre-translated: Number of pre-translated source segments, source words, characters, and the percentage of the text counted from the word count.
-
Fragments: Number of segments, source words, characters, and the percentage of the text counted from the word count, where there are fragment-assembled matches.
-
Edited: Number of edited source segments, source words, characters, and the percentage of the text counted from the word count.
-
Translator confirmed: Number of confirmed source segments, source words, characters, and the percentage of the text counted from the word count.
-
Reviewer 1 confirmed: Number of Reviewer 1 confirmed source segments, source words , characters, and the percentage of the text counted from the word count.
-
Reviewer 2 confirmed (proofread): Number of Reviewer 2 source segments, source words, characters, and the percentage of the text counted from the word count.
-
Locked: Number of locked source segments, source words, characters, and the percentage of the text counted from the word count.
-
Percentage ranges: These rows show the number of source segments, source words, characters, and the percentage of the text counted from the word count, for segments that have a match that falls in the same category.
For example, if you see 5 after 75-84%, when the resource is Every TM and corpus, and the scope is the Project, it means that the combination of all translation memories will give 75-84% matches for five segments.
Columns in the analysis report:
Each row (each Type) has a value in these rows:
-
Segments: Number of source segments of that type within the selected scope.
-
Source words: Number of source words of that type within the selected scope. If the Tag weight is not 0, this may be higher than the actual word count.
-
Source chars: Number of source characters of that type within the selected scope. Character counts include white space but do not include uninterpreted formatting tags. If the Tag weight is not 0, this may be higher than the actual character count.
-
Source tags: Number of tags included in the segments specified by the Type column, within the selected scope.
-
Percent: Percentage of the source words in this category against the total word count, within the selected scope. The sum of all percentages may not be precisely 100% because of rounding margins.
-
Target words: Number of target words of that type within the selected scope. This column appears only if the Include target counts checkbox is selected.
-
Target chars: Number of target characters of that type within the selected scope. This column appears only if the Include target counts checkbox is selected.
When you run Statistics for all the target languages of the project, you will get extra details:
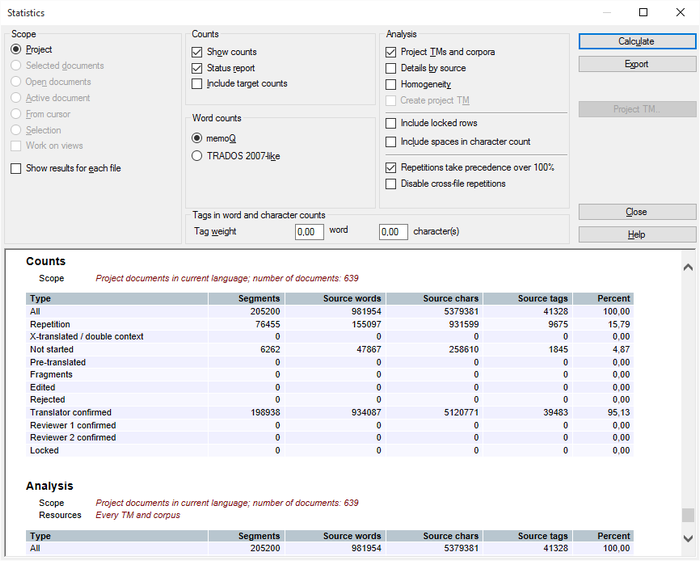
When you export the analysis, memoQ now adds a separate row for each target language document for the HTML and CSV (reflecting displayed results) options. If you choose to export as CSV (per-file, Trados-compatible) or CSV (per-file, all information), memoQ will export a CSV with a prefix for each target language, e.g. [ger] sample.txt:
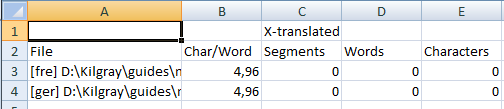
For source languages like Japanese or Chinese (no spaces between words), memoQ adds Source non-Asian words and Source Asian characters columns to the statistics results.
memoQ shows:
-
Source non-Asian words count instead of word count.
-
The combined Source words column includes Asian characters plus any non-Asian words.
Korean uses spaces, so word counting works similarly to European languages.