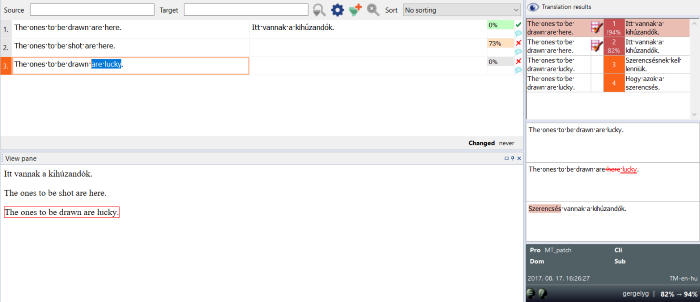
Volet Résultats
Pendant que vous traduisez, memoQ fonctionne en arrière-plan pour vous aider. Il tire des suggestions de diverses sources telles que les mémoires de traduction, les bases LiveDocs, les bases terminologiques, les correspondances de fragments’auto-substitution,
Lorsque vous entrez dans un nouveau segment, memoQ commence à interroger les ressources de traduction. Les différents types de ressources sont détaillés dans les sections ci-dessous.
Le volet des Résultats comprend trois sections :
La section supérieure :
La section supérieure du volet de Résultats affiche une liste de résultats de traduction provenant de toutes les ressources de traduction.
- Dans la colonne de gauche se trouve l’entrée en langue source de la ressource.
- La colonne du milieu affiche un chiffre d’identification.
- La colonne de droite contient l’équivalent en langue cible, s’il y en a un.
Si la liste contient plusieurs résultats, vous pouvez vous déplacer vers le haut et vers le bas dans la liste en utilisant les touches Ctrl+Haut et Ctrl+Bas.
Vous utilisez le clavier numérique? Vous devez désactiver la Touche de verrouillage du pavé numérique pour les raccourcis avec les touches Page haut, Page bas, Début, Fin, Haut ou Bas.
La couleur de fond indique la ressource dont chaque résultat provient :
Les suggestions provenant de mémoires de traduction ou de bases LiveDocs s’affichent en rouge. memoQ compare le segment source actuel à ceux stockés dans les différentes mémoires de traduction ajoutées au projet.
L’algorithme de comparaison utilise des lettres et des mots, mais pas leur signification. Ne soyez pas surpris si certains segments que memoQ trouve similaires ont en réalité des significations assez différentes.
Il existe trois types de correspondances « rouges » (de type résultat de MT) :
-
 – cette correspondance provient d’un document bilingue dans une base LiveDocs.
– cette correspondance provient d’un document bilingue dans une base LiveDocs. -
 – cette correspondance provient d’une paire de fichiers alignés dans une base LiveDocs.
– cette correspondance provient d’une paire de fichiers alignés dans une base LiveDocs. -
 – cette correspondance provient d’une mémoire de traduction (MT).
– cette correspondance provient d’une mémoire de traduction (MT).
Si une correspondance provient d’une mémoire de traduction, vous pouvez modifier l’entrée : Cliquez avec le bouton droit sur l’élément dans la liste de Résultats, puis dans le menu,
Les correspondances de MT ont un taux de correspondance en pourcentage : Ce chiffre montre la similarité entre le texte source dans la correspondance et le texte source dans le segment actuel.
Lorsque vous obtenez une correspondance provenant d’une mémoire de traduction ou d’une base LiveDocs, memoQ attribue une note à la correspondance. La note montre à quel point le segment source actuel est similaire au segment que memoQ a trouvé dans la ressource. Vous pouvez recevoir une correspondance en contexte, une correspondance exacte ou une correspondance partielle. Voici ce que chacune d’entre elles signifie :
-
Correspondances en contexte : Dans le texte suivi, le segment source est exactement identique à celui dans la ressource. Le segment précédent et le segment suivant sont également identiques (dans le texte source). Dans les documents ou tableaux structurés (XML), le segment source et son identifiant de contexte sont identiques à celui dans la ressource. Si le document contient du texte suivi et des identifiants de contexte, et s’il y existe une correspondance où les deux sont identiques, nous appelons cela une correspondance à double contexte. Le pourcentage de correspondance pour une correspondance en contexte simple est de 101 %. Le pourcentage de correspondance pour une correspondance en double contexte est de 102 %.
-
Correspondances exactes : Le segment source est exactement le même dans le document et dans la ressource, mais le contexte est différent. Le pourcentage de correspondance est de 100 %.
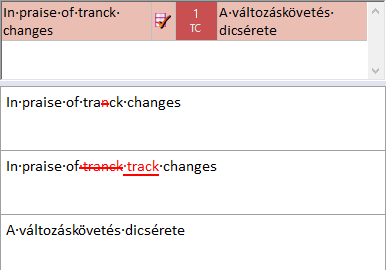
Une correspondance avant suivi des modifications (correspondance TC) est une correspondance exacte ou en contexte spéciale. Vous voyez ces éléments lorsque votre document source contient du suivi des modifications. Vous pouvez utiliser cette fonction si vous avez traduit un document dans le passé, et avez maintenant besoin d’en traduire une version modifiée. Parce que les modifications sont toutes marquées, memoQ sait quel était le texte avant modification. memoQ cherche le texte source avant modification – comme si toutes les modifications actuelles étaient rejetées – et renvoie des correspondances s’il y en a. Une correspondance TC est une correspondance exacte pour la version non modifiée du segment source.
- Correspondance partielle élevée : Le pourcentage de correspondance se situe entre 95 % et 99 %. Le texte est le même dans le document et dans la ressource, mais il y a des différences de chiffres, de signes de ponctuation, de balises ou d’espaces.
- Correspondance partielle moyenne 1 : Le pourcentage de correspondance se situe entre 85 % et 94 %. Dans des segments de longueur moyenne (environ 10 mots), il y a généralement une différence d’un mot entre le document et la ressource.
- Correspondance partielle moyenne 2 : Le pourcentage de correspondance se situe entre 75 % et 84 %. Dans des segments de longueur moyenne (environ 10 mots), il y a généralement une différence de deux mots entre le document et la ressource.
- Correspondances partielles peu élevées : Le pourcentage de correspondance se situe entre 50 % et 74 %. Cette différence est généralement trop importante, et la correspondance n’est pas utile – sauf si le segment source est très court (moins de 6 mots). Pour segments courts, les correspondances assez élevées peuvent avoir un pourcentage de correspondance faible.
memoQ affiche les résultats de recherche provenant des mémoires de traduction et des bases LiveDocs. Lors de la traduction de fichiers XLIFF :doc, vous pourriez également rencontrer des correspondances stockées avec des segments traduits. L’ordre de priorité des résultats de traduction est le suivant :
-
Le pourcentage de correspondance le plus élevé est affiché en premier.
-
Lorsqu’il y a plusieurs résultats avec le même pourcentage de correspondance, leur ordre d’affichage est le suivant :
- Résultats avec pourcentage de correspondance associé – uniquement dans les fichiers XLIFF :doc
- Résultats de la mémoire de traduction ultime
- Résultats des bases LiveDocs
- Résultats de la mémoire de traduction de travail
- Résultats provenant d’autres mémoires de traduction (de référence)
-
Lorsqu’il y a plusieurs résultats dans l’une de ces catégories, la plus récente (c’est-à-dire celle avec la date de modification la plus récente) apparaît en premier.
Les suggestions des bases terminologiques s’affichent en bleu. memoQ vérifie chaque mot et expression dans le segment source, et offre une suggestion pour chaque élément trouvé dans les bases terminologiques du projet.
Il existe trois types de correspondances « bleues » (remontées de bases terminologiques) :
-
 – La correspondance provient d’une base terminologique régulière. Dans de nombreux environnements, ceci est considéré comme la source faisant autorité.
– La correspondance provient d’une base terminologique régulière. Dans de nombreux environnements, ceci est considéré comme la source faisant autorité. -
 – La correspondance provient d’une entrée acceptée au cours d’une session d’extraction de candidats.
– La correspondance provient d’une entrée acceptée au cours d’une session d’extraction de candidats. -
 – La correspondance provient d’un service de terminologie externe. Pour en savoir plus, consultez la catégorie Plugins de terminologie des Options.
– La correspondance provient d’un service de terminologie externe. Pour en savoir plus, consultez la catégorie Plugins de terminologie des Options.
Lorsque vous sélectionnez une entrée de base terminologique dans la liste des résultats, les détails de l’entrée apparaissent sous la liste, dans une présentation formatée.
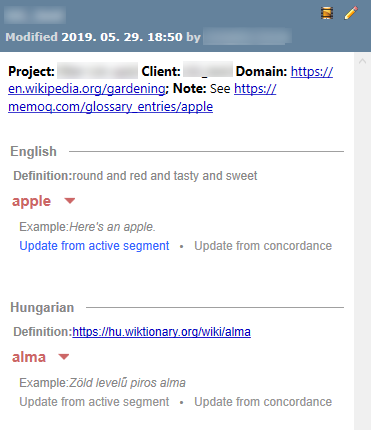
- Seuls les termes des langues du projet sont affichés, avec le terme source en premier, et le ou les termes cibles en dessous.
- Seul le contenu du terme sélectionné dans la liste des Résultats est développé (termes source et cible), tous les autres termes de l’entrée sont réduits.
Pour développer ou réduire les informations d’un terme : À droite du terme, cliquez sur le symbole de triangle pointant vers le bas ou vers la droite.
Pour modifier une entrée de base terminologique : Cliquez ![]() dans le coin supérieur droit. La fenêtre Éditer l’entrée de base terminologique s’ouvre.
dans le coin supérieur droit. La fenêtre Éditer l’entrée de base terminologique s’ouvre.
Pour ajouter le segment actuel à l’entrée terminologique à titre d’exemple : Sous la langue que vous souhaitez mettre à jour, cliquez sur Mettre à jour à partir du segment actif.
Pour ajouter une concordance à l’entrée terminologique à titre d’exemple : Sélectionnez une phrase dans l’éditeur de traduction, appuyez sur Ctrl+K, sélectionnez le résultat de concordance que vous souhaitez ajouter, et sous la langue que vous souhaitez mettre à jour, cliquez sur Mettre à jour à partir de la concordance.
Pour copier l’information sur le terme : Sélectionnez les métadonnées du niveau Entrée de la fiche (dans l’image ci-dessus, Projet et Client), du niveau Langue (Définition) et celles du niveau Terme (Exemple) avec votre souris. Appuyez sur Ctrl+C ou, cliquez avec le bouton droit de la souris n’importe où dans cette zone, et choisissez Copier la sélection, Copier l’information sur la paire de termes, ou Copier l’information sur l’entrée dans le menu.
Si le projet sur lequel vous travaillez contient une base terminologique Qterm, vous pouvez également ajouter des entrées et modifier les entrées existantes dans la base terminologique Qterm (si vous avez les permissions nécessaires).
Une correspondance provenant d’une base terminologique Qterm ressemble à ceci :
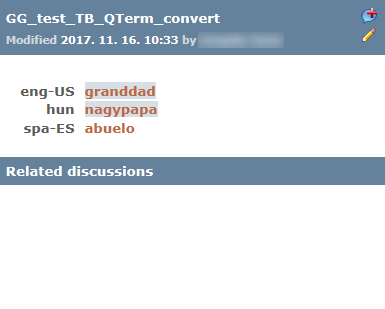

Vous pouvez également démarrer une discussion pour une entrée de base terminologique Qterm :
-
Cliquez sur l’icône Discussion
 : la boîte de dialogue Démarrer une discussion s’affiche.
: la boîte de dialogue Démarrer une discussion s’affiche. -
Entrez un résumé, un énoncé de problème et une résolution suggérée. S’il existe déjà des discussions pour l’entrée, elles sont répertoriées sous les termes, dans Discussions associées.
-
Pour contribuer à une conversation : Cliquez sur le titre de la discussion. La fenêtre Discussions s’ouvre.
Vous ne pouvez pas ajouter de discussions ou y participer si les discussions sont désactivées sur le serveur, dans Qterm, ou si vous êtes membre d’un groupe exclu des discussions.
Vous pouvez également démarrer une discussion pour une entrée de base terminologique Qterm. Cliquez sur l’icône Discussion ![]() : la boîte de dialogue Nouvelle discussion apparaît où vous pouvez entrer un résumé, un énoncé de problème et une résolution suggérée. S’il existe déjà des discussions pour l’entrée, elles sont répertoriées sous les termes, dans Discussions associées. Pour participer à une discussion, cliquez sur le titre de la discussion : cela ouvre la fenêtre des Discussions.
: la boîte de dialogue Nouvelle discussion apparaît où vous pouvez entrer un résumé, un énoncé de problème et une résolution suggérée. S’il existe déjà des discussions pour l’entrée, elles sont répertoriées sous les termes, dans Discussions associées. Pour participer à une discussion, cliquez sur le titre de la discussion : cela ouvre la fenêtre des Discussions.
Remarque : Vous ne pouvez pas ajouter de discussions ou y participer si les discussions sont désactivées sur le serveur, dans Qterm, ou si vous êtes membre d’un groupe exclu des discussions.
Lorsqu’il y a de nombreux résultats de terminologie : memoQ les trie et en masque même certains, afin de vous offrir la liste la plus pertinente. Par défaut, les résultats sont affichés dans l’ordre dans lequel ils apparaissent dans le texte source. Si une partie du texte source est couverte par plusieurs résultats de terminologie, la correspondance la plus longue masque la plus courte (si vous cliquez sur l’icône de l’œil ![]() , les plus courtes apparaîtront également). S’il y a plusieurs résultats pour la même expression source, les résultats seront classés selon le rang de la base terminologique et leurs métadonnées : si deux résultats de base terminologique proviennent de la même base terminologique, mais l’un d’eux a plus en commun avec le projet que l’autre, il l’emporte. Pour en savoir plus :
, les plus courtes apparaîtront également). S’il y a plusieurs résultats pour la même expression source, les résultats seront classés selon le rang de la base terminologique et leurs métadonnées : si deux résultats de base terminologique proviennent de la même base terminologique, mais l’un d’eux a plus en commun avec le projet que l’autre, il l’emporte. Pour en savoir plus :
Les termes interdits s’affichent en noir et proviennent des bases terminologiques. Ils montrent comment un terme (ou une expression) dans la langue source ne doit pas être traduit. Ces correspondances ne peuvent pas être insérées dans la traduction, mais elles sont affichées pour avertir le traducteur. Si vous utilisez un terme interdit, vous recevrez un avertissement de contrôle qualité.
Les suggestions d’assemblage de fragments sont violettes. memoQ tente de d’assembler la traduction du segment source à partir de ses parties plus petites qui sont trouvées soit dans les mémoires de traduction, soit dans les bases terminologiques du projet.
Pour en savoir plus : Consultez la page de documentation sur l’assemblage de fragments.
Pour activer ou désactiver la recherche automatique de fragments : Dans la fenêtre des Options, à gauche, cliquez sur la catégorie Recherche étendue. Cliquez ensuite sur l’onglet Assemblage de fragments.
Les suggestions de concordances automatisées (ou correspondance automatique de fragments, LSC) s’affichent en orange clair. memoQ tente de récupérer les expressions les plus longues possibles par concordance, et essaie également de proposer un équivalent. Si memoQ trouve une traduction, elle s’affiche dans la liste. Vous pouvez insérer cette traduction dans le segment cible de la même manière que les correspondances de la MT.
En l’absence de traduction : En double-cliquant sur la suggestion, vous ouvrirez la fenêtre Concordance, où vous pourrez trouver et insérer la traduction.
Pour activer ou désactiver les correspondances de concordance automatisées : Dans la fenêtre des Options, à gauche, cliquez sur la catégorie Recherche étendue.
Si au moins un plug-in de traduction automatique est configuré, et que le paramètre Grille de traduction n’est pas Désactivé dans l’onglet Paramètres de la fenêtre Modifier les paramètres de traduction automatique, memoQ demande des suggestions à un service de traduction automatique. Ces suggestions s’affichent en orange foncé. Vous pouvez les insérer dans le segment cible de la même manière que les correspondances de la MT.
Les suggestions de concordance de TA (versions de la phrase sélectionnée traduites automatiquement) sont jaunes. Vous pouvez insérer ces traductions dans le segment cible comme des correspondances de la base terminologique – elles ne remplacent pas le contenu déjà présent.
Les Termes à ne pas traduire apparaissent en gris. Ces éléments ne doivent pas être traduits. En utilisant ces suggestions, vous pouvez insérer exactement le même mot ou la même expression dans le segment cible.
Les résultats des règles d’auto-substitution s’affichent en vert. Les règles d’auto-substitution sont des expressions modèles que memoQ recherche dans le segment source. Certains éléments linguistiques ont de nombreuses combinaisons, et ne peuvent pas être énumérés, mais peuvent être décrits en utilisant des règles spéciales. Ces éléments comprennent les dates, les mesures, les conversions de devises, etc.
La section du milieu :
Lorsque vous sélectionnez une correspondance de bases LiveDocs ou une correspondance de mémoire de traduction dans le volet Résultats, d’autres détails s’affichent dans trois sections juste en-dessous de la liste.
Ces zones de comparaison montrent :
- d’abord le segment source actuel;
- ensuite le texte source de la suggestion sélectionnée;
- enfin le texte cible de la suggestion sélectionnée.
Vous pouvez choisir entre deux vues. Lorsque vous recevez votre premier résultat de TA, une notification s’affiche :
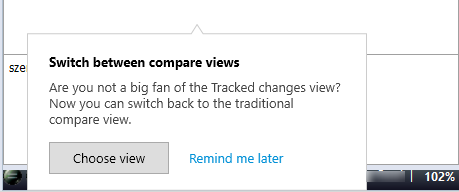
Pour faire un choix plus tard : Cliquez sur Me le rappeler plus tard. memoQ continue d’utiliser l’aperçu du suivi des modifications. La même notification s’affichera plus tard.
Pour faire un choix tout de suite : Cliquer sur Sélectionner l’aperçu. La fenêtre Comparer les différentes vues s’ouvre (voir ci-dessous).
Si vous avez fait un choix et que vous voulez le changer :
-
Au-dessus de la liste des Résultats, double-cliquez sur l’icône de l’œil
 .
. -
Dans la fenêtre des Paramètres des résultats de traduction, sous la section Zones de comparaisons, sélectionnez Aperçu du suivi des modifications ou Vue comparée classique.
OU :
-
Dans le coin supérieur gauche de memoQ, à partir de la barre d’outils Accès rapide, cliquez sur l’icône Options
 .
. -
Dans la liste latérale gauche de la fenêtre Options, cliquez sur la catégorie Divers.
-
Dans l’onglet Résultats des interrogations, sous la section Zones de comparaison, sélectionnez Aperçu du suivi des modifications ou Vue comparée classique.
Pour voir la différence : Cliquez sur la mention Comparer les différentes vues.
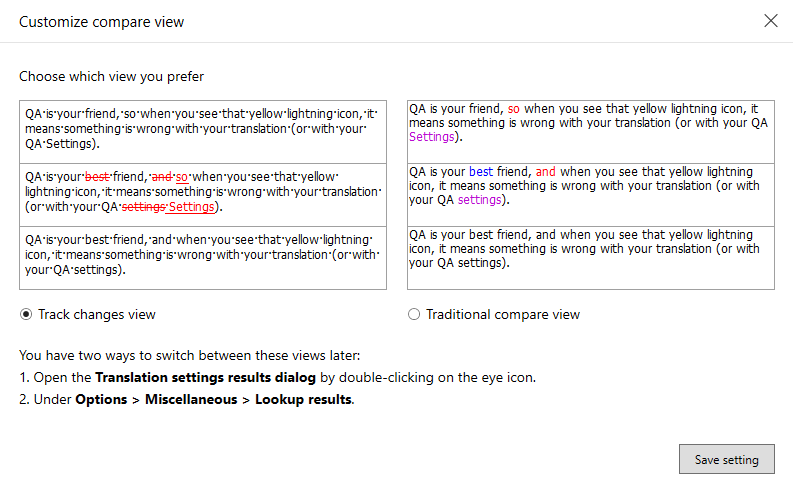
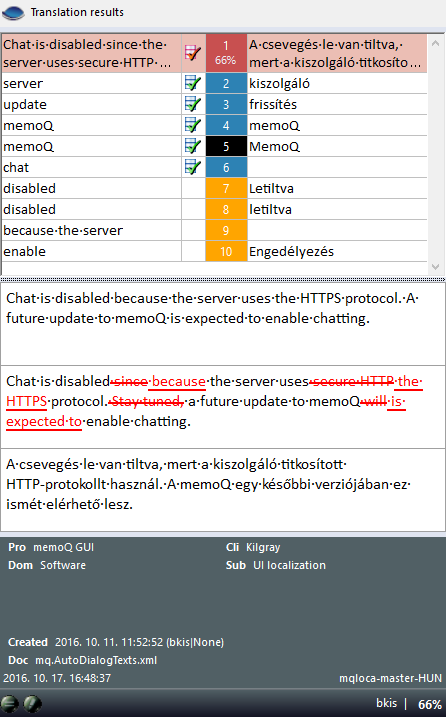
Aperçu du suivi des modifications :
Les différences entre les deux segments sources s'affichent sous forme de suivi de modification, de la même façon que le suivi des modifications dans le texte.
Les modifications sont mises en évidence dans la deuxième zone seulement, comme si la correspondance de mémoire de traduction avait été corrigée dans le segment source actuel. Ce qui signifie que :
- Les nouvelles parties qui sont présentes dans le segment source actuel apparaissent comme des insertions;
- Les anciens éléments qui apparaissent dans la correspondance (seulement) s’affichent comme des suppressions.
Vue comparée classique :
memoQ utilise un code de couleurs pour mettre en évidence les différences entre le résultat de traduction et le texte source.
- Noir : parties identiques dans la source et dans la correspondance.
- Rouge : différences entre la première et la seconde zones de comparaison. Examinez les parties surlignées et ajustez la suggestion au texte source.
- Bleu : Un mot est manquant dans la suggestion. Ajoutez-le dans votre traduction.
Pour changer la couleur des marques de suivi : Utilisez l’onglet Zones de comparaison de la catégorie Apparence du menu Options pour modifier les couleurs selon vos besoins.
Pour changer les polices et les couleurs des polices : Utilisez l’onglet Grille de traduction de la catégorie Apparence du menu Options pour modifier ces couleurs et polices. Cette page de documentation présente les paramètres par défaut; si vous les modifiez, cette description pourrait ne plus correspondre à ce que vous voyez dans votre instance de memoQ.
La section inférieure :
En dessous des trois zones de comparaison, memoQ affiche les champs descriptifs de la suggestion sélectionnée.
Pour les entrées de mémoire de traduction, vous obtenez les informations suivantes :
- la métadonnée Suj, ou sujet;
- la métadonnée Dom, ou domaine;
- la métadonnée Pro, ou identifiant de projet;
- la métadonnée Cli, ou le client pour lequel la mémoire de traduction a été faite;
- le nom de la mémoire de traduction ou de la base LiveDocs d’où provient l’entrée;
- le nom d’utilisateur de la personne qui a créé ou modifié l’entrée pour la dernière fois;
- la date et l’heure de création ou de modification de l’entrée;
- le pourcentage de correspondance de la suggestion;
- le rôle d’utilisateur stocké dans la mémoire de traduction. Cette entrée a-t-elle été confirmée par un traducteur, un relecteur 1 ou un relecteur 2?
Il y a deux ensembles de petits indicateurs lumineux au bas du volet des Résultats lorsqu’une correspondance de mémoire de traduction est sélectionnée dans la liste de la section supérieure :
![]()
Les deux indicateurs lumineux de gauche indiquent si l’entrée sélectionnée est le résultat d’un alignement automatique  , ou si le texte du segment source a été modifié dans l’éditeur de traduction puis réenregistré dans la mémoire de traduction
, ou si le texte du segment source a été modifié dans l’éditeur de traduction puis réenregistré dans la mémoire de traduction  . Par exemple, s’il y a une faute de frappe dans le segment source, vous pouvez faire un clic droit sur le segment en question et choisir l’option Éditer le segment source. Corrigez le segment source, puis cliquez sur Ctrl+Entrée pour enregistrer vos modifications. C’est dans ce cas que vous verrez cet indicateur lumineux allumé lorsque vous revenez à ce segment dans la grille de traduction.
. Par exemple, s’il y a une faute de frappe dans le segment source, vous pouvez faire un clic droit sur le segment en question et choisir l’option Éditer le segment source. Corrigez le segment source, puis cliquez sur Ctrl+Entrée pour enregistrer vos modifications. C’est dans ce cas que vous verrez cet indicateur lumineux allumé lorsque vous revenez à ce segment dans la grille de traduction.
Le chef de projet peut autoriser ou interdire aux traducteurs de modifier le texte source.
Six autres indicateurs apparaissent lorsque la correspondance de mémoire de traduction sélectionnée est comprise entre 95 % et 101 %. Ces indicateurs, lorsqu’ils sont allumés, indiquent des différences mineures entre le texte du segment source actuel et le texte source de l’entrée de MT (par exemple, segment précédemment en gras, maintenant en italique).
-
 – moins ou plus de caractères d’espacement que dans l’entrée en MT
– moins ou plus de caractères d’espacement que dans l’entrée en MT -
 – ponctuation différente
– ponctuation différente -
 – majuscule/minuscule différente
– majuscule/minuscule différente -
 – mise en forme gras/italique/souligné différente
– mise en forme gras/italique/souligné différente -
 – balises différentes
– balises différentes -
 – nombres et entités différents
– nombres et entités différents
Si un indicateur est allumé (s’affiche en couleur), alors vous devez corriger ce type de différence manuellement. Si l’indicateur est légèrement éclairé, en gris, cela vous indique que memoQ a détecté une différence, mais l’a déjà corrigée pour vous. Par exemple, memoQ peut appliquer une mise en forme en gras au segment cible entier ou remplacer les nombres pour correspondre à ceux du texte source, et ainsi de suite.
Pour les termes, vous verrez la même information à l’exception de l’étiquette Aligné et du pourcentage de correspondance de l’entrée.
Pour que les différences de nombres et d’entités vous soient indiquées, vous devez modifier les paramètres par défaut du TM. À partir de l’onglet Accueil du projet, choisissez Paramètres, puis cliquez sur l’onglet Paramètres de MT. Clonez les paramètres par défaut. Puis cliquez sur Éditer, et décochez la case Ajuster la mise en forme et la case des lettres. À partir de maintenant, memoQ n’ajustera pas les chiffres, mais allumera l’indicateur lumineux.
Plus d’information
En haut du volet Résultats, l’icône d’œil fermé  indique des suggestions masquées provenant des mémoires de traduction, des bases LiveDocs et des bases terminologiques. Habituellement, memoQ fonctionne ainsi.
indique des suggestions masquées provenant des mémoires de traduction, des bases LiveDocs et des bases terminologiques. Habituellement, memoQ fonctionne ainsi.
Pour afficher toutes les suggestions, cliquez sur cette icône. Ou, appuyez sur Ctrl+Maj+ D pour ouvrir l’œil  .
.
Pour choisir et vérifier quelles suggestions sont masquées, consultez la page de documentation sur la fenêtre des Paramètres des résultats de traduction.
Lorsque vous avez un segment source long, et qu’il n’y a pas de correspondance dans les mémoires de traduction, memoQ peut rechercher de petites parties de ce segment dans les mémoires de traduction et les bases terminologiques assignées au projet. Si des segments plus courts se trouvent dans les mémoires de traduction ou les bases terminologiques (avec leurs traductions), memoQ tente de chercher des parties plus courtes (fragments) de votre long segment, et d’insérer leurs traductions dans le segment cible. Cette action est automatique : lorsque vous passez à un segment, et memoQ recherche dans les mémoires de traduction et les bases terminologiques, les correspondances « rapiécées » ou les correspondances fragmentées, s’il y en a, apparaîtront automatiquement dans la liste des résultats.
Par défaut, les correspondances de fragments apparaissent en violet dans la liste des résultats. Vous pouvez y accéder en appuyant sur Ctrl+Flèche bas. Appuyez ensuite sur Ctrl+Espace pour les insérer. Vous pouvez également double-cliquer sur le résultat dans la liste, ou maintenir la touche Ctrl, puis appuyez sur la touche correspondant au numéro du résultat, s’il y en a un (les 9 premiers résultats sont numérotés).
Supposons que vous avez traduit les segments suivants dans le passé :

... et vous avez l’entrée suivante dans votre base terminologique :
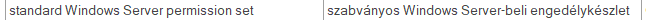
Vous devez maintenant traduire le segment suivant dans un autre document :

Pour remplir la traduction pour le segment ci-dessus, il suffit de placer le curseur dans le segment cible. memoQ trouvera automatiquement les deux segments plus courts dans la mémoire de traduction, ainsi que l’entrée de la base terminologique pour le terme à la fin du segment. La traduction assemblée apparaîtra automatiquement dans la liste des résultats :
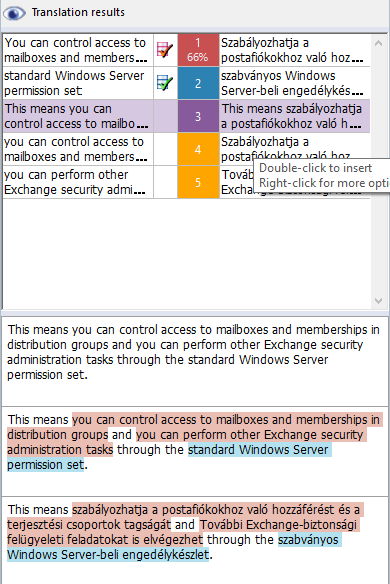
Pour insérer la suggestion de traduction, appuyez sur Ctrl+3 ou utilisez Ctrl et les touches fléchées pour naviguer jusqu’à la suggestion, puis appuyez sur Ctrl+Espace.
Lorsque memoQ tente d’assembler une traduction à partir de fragments, elle cherchera toujours le fragment le plus long possible à partir du début du segment. Lorsqu’un fragment est trouvé, memoQ cherche à nouveau le fragment le plus long possible à partir du point où le fragment précédent s’est terminé. S’il ne trouve pas un fragment depuis le début du segment (ou le point où le fragment précédent s’est terminé), il tente de chercher un fragment à partir du mot suivant. Si les recherches suivantes sont également infructueuses, memoQ passe d’un mot à l’autre jusqu’à ce qu’un fragment soit trouvé ou que la fin du segment soit atteinte.
Lors de la recherche de fragments, memoQ effectue des recherches dans les mémoires de traduction et les bases terminologiques du projet. Lors de la recherche des mémoires de traduction, memoQ utilise uniquement les correspondances exactes de la mémoire de traduction. Il ne tente pas de trouver des correspondances approximatives pour les fragments dans les mémoires de traduction. Lors de la recherche des bases terminologiques, memoQ n’utilise pas la correspondance de préfixe.
Lors de l’assemblage d’une traduction à partir de fragments, memoQ couvre toujours l’ensemble du segment source. Lors de la recherche de fragments, memoQ opère toujours mot par mot. Si un mot n’est pas couvert par une correspondance de fragment, c’est-à-dire que memoQ a dû sauter un mot et continuer la recherche à partir du suivant, l’écart sera comblé en insérant ce mot dans la langue source. Voir l’exemple ci-dessus : il reste encore du texte anglais dans la suggestion. Cela est dû au fait que memoQ n’a pas trouvé d’entrées de MT ou de BT pour traduire ces mots.
La plupart du temps, l’assemblage de fragments remplace les termes du texte source. Lorsqu’il y a deux résultats de base terminologique ou plus pour les mêmes mots source, memoQ doit en choisir un. Pour cette raison, memoQ attribue une note aux résultats de terminologie, et celui avec la note la plus élevée l’emporte.
Bien sûr, le résultat le plus long est toujours plus fort, mais lorsque les résultats sont aussi longs les uns que les autres, memoQ doit les examiner de plus près.
D’une part, vous pouvez établir des priorités entre les bases terminologiques : si un terme provient d’une base terminologique d’un rang plus élevé, il l’emportera.
D’autre part, s’ils proviennent de la même base terminologique, memoQ a encore besoin d’un moyen de décider.
Ce processus fonctionne si le classement est activé. Pour activer le classement, ouvrez la boîte de dialogue Paramètres des résultats de traduction, et cochez la case Classer les résultats de la base terminologique selon leur rang et leurs métadonnées.
memoQ vérifie à quel point un résultat de terminologie est pertinent pour le projet. Si une base terminologique contient deux éléments correspondants au projet, et une autre en compte trois, alors c’est celle contenant trois éléments qui emporte.
Si les résultats de bases terminologiques ont un nombre d’éléments correspondant au projet équivalents, memoQ vérifie l’importance de ces éléments. L’ordre d’importance, du plus important au moins important, est le suivant :
- Nom du projet
- Nom du client
- Sujet
- Domaine
Par exemple, si un résultat de terminologie contient la même métadonnée client, et un autre contient le même sujet, le premier des deux résultats l’emporte car la métadonnée client est plus importante que le sujet.
Lorsque memoQ trouve un terme dans le texte, il apparaît dans la liste des suggestions. Mais dans l’exemple ci-dessous, on retrouve à la fois une correspondance de mémoire de traduction et un résultat de terminologie provenant tous deux des ressources (c’est-à-dire la mémoire de traduction et la base terminologique), et memoQ les combine :
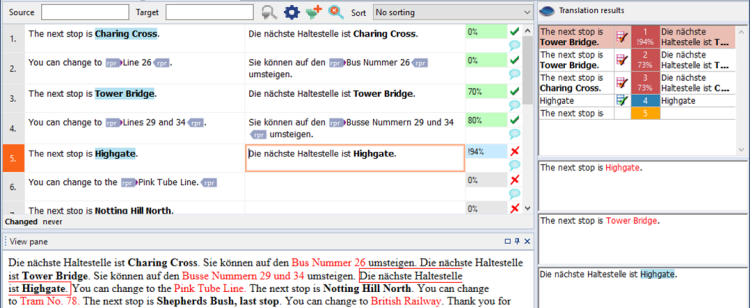
Notez que memoQ a inséré une traduction absolument parfaite. Comment cela est-il possible si la correspondance de la mémoire de traduction était « The next stop is Tower Bridge? »?
La différence entre le texte source et la correspondance des mémoires de traduction était le nom de la station : « Highgate » dans le texte source, et « Tower Bridge » dans la traduction. Les deux noms étaient également présents dans la base terminologique. memoQ a pu trouver la traduction de « Tower Bridge » dans la traduction enregistrée, et comme il savait déjà comment traduire « Highgate », l’ancien nom a pu être facilement remplacé par le nouveau.
Lorsque cela se produit, nous disons que memoQ rapièce la traduction. memoQ attribue également une note plus élevée à la traduction rapiécée, mais la marque d’un point d’exclamation (! – voir le champ d’état bleu à côté du segment).
Pour que cela fonctionne, ouvrez la fenêtre Options. Choisissez la catégorie Divers. Cliquez sur l’onglet Résultats des interrogations. Cochez la case Rapiécer les correspondances partielles de la MT.
Pour en savoir plus : Consultez la page de documentation sur les Options.
memoQ montre une correspondance rapiécée avec un point d’exclamation avant le pourcentage de correspondance : !93 %. Au bas du volet de Résultats, deux pourcentages de correspondance s’affichent. 73 %->93 %. Cela signifie que la correspondance était initialement de 73 %, mais memoQ a réussi à l’améliorer pour atteindre 93 %.
memoQ utilise également la mise en forme du segment source. Si votre terme est formaté en gras, le terme cible sera également inséré en gras.
memoQ recherche chaque différence dans les correspondances partielles. Donc, en théorie, il peut rapiécer le tout; mais en pratique, généralement une ou deux différences sont rapiécées. Cela se produit parce que le rapiècement de correspondances a besoin de correspondances élevées, et que quelques résultats dans les documents de référence sont suffisants. Le rapiècement pour la traduction automatique a également certaines limites :
-
memoQ consulte des expressions dans un seul service de TA, une seule fois, et prend seulement la première traduction proposée. Si cette traduction diffère de celle dans la correspondance partielle de la mémoire de traduction, memoQ ne peut pas la rapiécer.
-
memoQ ne cherche pas les mots contenant trois lettres ou moins.
Vous devez toujours ajuster la fin du segment, selon votre langue cible. Dans la grille, les correspondances rapiécées sont indiquées en bleu clair, différemment des segments « standard » prétraduits.
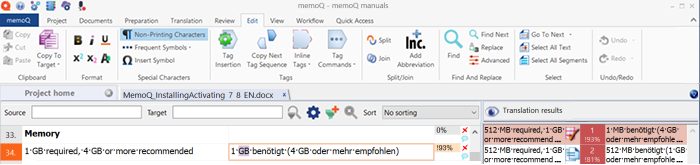
Aucun rapiècement pendant la prétraduction : memoQ n’ajustera pas les correspondances pendant la prétraduction.
Ne pas rapiécer les numéros ou les balises : La mémoire de traduction s’en charge. Le rapiècement des correspondances fonctionne avec les différences de texte seulement.
Les correspondances rapiécées portent une pénalité : Une correspondance corrigée peut être parfaite (exacte), mais memoQ applique une pénalité. Le pourcentage de correspondance d’une correspondance partielle rapiécée ne dépasse jamais 94 %.
Exemple 1 :
Texte source en anglais :Chocolate was the best-selling commodity in the last summer.
Ressources :
La phrase ci-dessus a été stockée dans votre MT avec la bonne traduction en allemand. Schokolade war die meist verkaufteste Ware im letzten Sommer.
Votre base terminologique contient le terme : ice cream = Eiscreme
Vous recevez maintenant un nouveau texte en anglais contenant la phrase :
Ice cream was the best-selling commodity in the last summer.
La phrase en allemand dans la cible :Eiscreme war die meist verkaufte Ware im letzten Sommer.
Exemple 2 :
Texte source en anglais : Chocolate was the best-selling commodity in the last hot summer.
Ressources :
La phrase ci-dessus a été stockée dans votre MT avec la bonne traduction en allemand. Schokolade war die meist verkaufte Ware im letzten heißen Sommer.
Votre base terminologique contient le terme : ice cream = Eiscreme and cold = kalten
Vous recevez maintenant un nouveau texte en anglais contenant la phrase :
Ice cream was the best-selling commodity in the last cold summer.
La phrase en allemand dans la cible :Eiscreme war die meist verkaufte Ware im letzten kalten Sommer.
Si vous avez accès à un service de traduction automatique, vous pouvez également l’utiliser pour rapiécer les correspondances partielles provenant des vos MT.
- Ouvrez la fenêtre Modifier les paramètres de traduction automatique.
- Si nécessaire, cliquez sur la ligne du service de TA dans la liste et configurez le plug-in.
- Dans l’onglet Paramètres, choisissez un service dans le menu déroulant Correspondance.
- Cliquez sur OK.
Si la fonction MatchPatch ne peut pas rapiécer une correspondance partielle en utilisant les résultats des mémoires de traduction ou des bases terminologiques, elle utilise le service de TA sélectionné pour tenter un rapiècement.