統計
統計ウィンドウでは、プロジェクトまたは選択したドキュメント内の単語数、セグメント数、および文字数をカウントできます。翻訳メモリやライブ文書資料と照らし合わせて分析し、既に持っているリソースを考慮して、実際にどれだけの作業が必要かを調べることができます。
統計コマンドを使用し、分析に基づいて、このプロジェクトに対して請求する必要がある金額を確認します。
これは手動の方法です:プロジェクトテンプレートでは、memoQは分析レポートを自動的に実行できます。
これは微調整された方法です:プロジェクトの概要では、少ない設定でプロジェクト全体に対してクイック分析レポートを実行できます。
操作手順
- プロジェクトを開きます。または、プロジェクトを作成してドキュメントをインポートします。
- ドキュメントの一部を分析する必要がある場合は、翻訳用にドキュメントを開きます。
- 文書リボンで、統計をクリックします。
統計ウィンドウが開きます。
memoQ project managerが必要:オンラインプロジェクトを管理するには、memoQ project managerエディションが必要です。
プロジェクトマネージャまたは管理者である必要があります:オンラインプロジェクトを管理できるのは、memoQ serverのプロジェクト管理者または管理者グループのメンバーである場合、またはプロジェクトでプロジェクト管理者役割を持っている場合のみです。
- 管理対象のオンラインプロジェクトを開きます。または、オンラインプロジェクトを作成してドキュメントをインポートします。
- memoQ オンラインプロジェクトウィンドウで、翻訳を選択します。
- ドキュメントリストで、統計をクリックします。
統計ウィンドウが開きます。
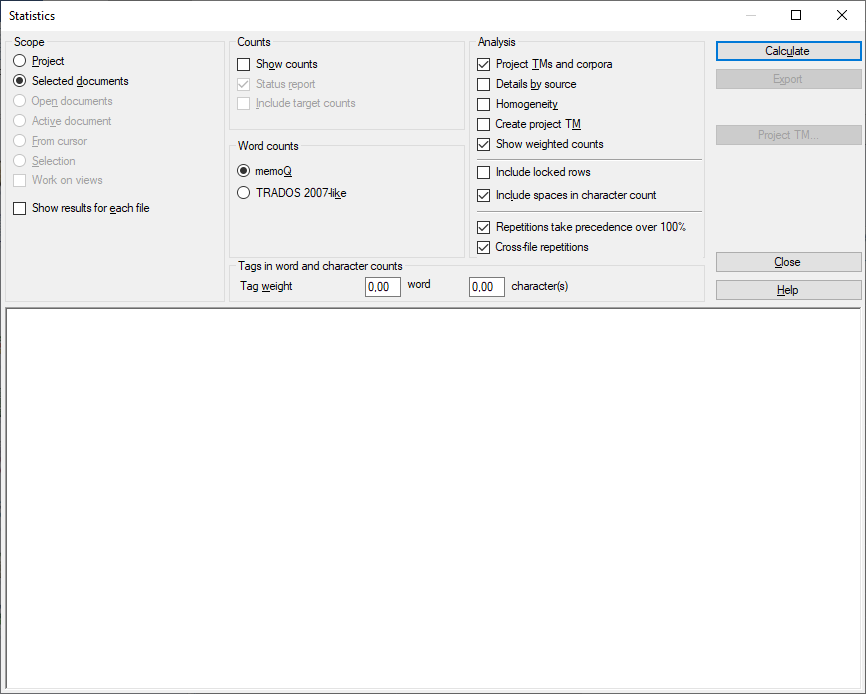
その他のオプション
これにより、対象とする文書の範囲を決めることができます。以下のオプション (ラジオボタン) から1つを選択します:
- プロジェクト:memoQは、現在のプロジェクトのすべてのドキュメントのすべてのセグメントを分析します。プロジェクトに複数のターゲット言語がある場合、memoQはすべてのターゲット言語のセグメントをチェックします。
- 作業中の文書:memoQは、作業中のドキュメント内のすべてのセグメントを分析します。作業中の文書とは、翻訳エディタで開かれ、表示されている文書を指します。翻訳エディタで文書を開いて作業中である場合のみこれを選択できます。
- 選択した文書:memoQは、選択したドキュメント内のすべてのセグメントを分析します。プロジェクトホームにある翻訳で複数の文書を選択している場合のみこれを選択できます。翻訳エディタを開いている場合は使用できません。
- カーソル以降:アクティブなドキュメントの現在の位置以降のセグメントを分析します。作業中の文書とは、翻訳エディタで開かれ、表示されている文書を指します。翻訳エディタで文書を開いて作業中である場合のみこれを選択できます。
- 開いている文書:翻訳エディタタブで開いているすべてのドキュメントのすべてのセグメントを分析します。
- 選択:作業中のドキュメントの選択したセグメントが分析されます。作業中の文書とは、翻訳エディタで開かれ、表示されている文書を指します。翻訳エディタで文書を開いて作業中である場合のみこれを選択できます。
- ビューで使用チェックボックス:現在のプロジェクトのビューにあるセグメントが対象となります。プロジェクトに少なくとも1つのビューが存在する場合のみこれを選択できます。
1つのターゲット言語でセグメントを分析するには:統計ウィンドウを開く前に、プロジェクトホームの翻訳ペインで言語を選択します。すべてのドキュメントを選択して統計を開き、選択した文書を選択します。
テキストを最初から翻訳する場合と比較して、翻訳メモリのマッチがある場合、理論的には作業量は少なくなります。仕事を始める前に、その仕事がどのくらいになるか考えておく必要があります。特に、一部のドキュメントの翻訳を新しいバージョンにアップデートする作業の場合です。この場合、実際の翻訳作業は、ソース文書の合計単語数の10% (またはそれ以下) に抑えることができるかもしれません。これは、テキストの多くは以前の翻訳を使用できるためです。
memoQでは、単語数が一致カテゴリ別にグループ化されています。100%一致するセグメント内の単語数、95~99%一致するセグメント内の単語数などがわかります。
各一致カテゴリに対して、加重を設定できます。加重値は0% (まったく作業しない) から100% (すべての単語を最初から翻訳する) の間です。カテゴリ内のワードカウントに加重を掛けます。これで理論上の加重されたワードカウントが得られます。
例:セグメントが90%一致する場合、通常は1単語の違いを意味します。その一致カテゴリー (85-94%) に対する加重は50%とします。セグメントが10語の場合、5語としてカウントします。
この設定を分析レポートを作成ウィンドウに設定するには、次のオプションを使用します:
これらの設定はローカルプロジェクト用です。
- プロジェクトの翻訳メモリと資料を使用チェックボックスをオンにします。これにより、memoQはプロジェクト内ですべての翻訳メモリとライブ文書資料を確認します。
- 均一性の計算チェックボックスをオンにします。memoQは内部のあいまい類似性も考慮します。つまり、memoQは、翻訳メモリが増大していく翻訳中に何が一致するかを予測します。
これは、あなたが一人でするジョブでのみ使用してください:他の翻訳者も参加する仕事では、均一性の計算チェックボックスにチェックマークを入れないでください。
- ロックされた行を含めるチェックボックスをオフにします:受け取った文書の一部がロックされているということは、通常、クライアントはあなたにその部分を編集してほしくないということです。
- 繰り返しを100%一致よりも優先チェックボックスにチェックマークが入っていることを確認します:このオプションは、翻訳メモリから一致するものをすべて使用するよりも、一貫した翻訳が重要な場合に使用します。
- クロスファイル繰り返しチェックボックスにチェックマークが入っていることを確認します:プロジェクト内のすべての文書を一人で翻訳するため、文書間にまたがる繰り返しを利用できます。他のユーザーもこのジョブで作業する場合にのみ、このチェックボックスをオフにします。
- 加重カウントを表示チェックボックスをオンにします。memoQは、ジョブのおおよその「実際の」単語数を計算します。そのために、memoQはオプション (その他カテゴリ、加重カウント) で設定された加重を使用します。
オンラインプロジェクトを管理?オンラインプロジェクトで統計を実行している場合、memoQ serverの加重を使用します。memoQ serverに加重を設定するには、サーバーマネージャを使用します。加重カウントを選択し、加重をチェックまたは設定します。
複数の文書で複数の翻訳者が作業する場合、どの翻訳者がどのセグメントまたはどの文書をいつ翻訳するか、事前に知ることはできません。誰が他の人の翻訳を使うことができるかわかりません。その結果、どの内部反復が使用されるかを予測できません。
結論:翻訳が1人の翻訳者ではなくチームにより行われる場合、正確な作業量を前もって知ることはできません。実際の作業量を知るには、翻訳の完了後に翻訳後分析を実行します。
分析レポートを作成ウィンドウでチームにこれを設定するには、これらの設定を使用します:
これらの設定は、オンラインプロジェクト用です。プロジェクトマネージャで、プロジェクトをサーバーに公開するか、パッケージを使用してプロジェクトを配布する場合は、ローカルプロジェクトでも使用します。
- プロジェクトの翻訳メモリと資料を使用チェックボックスをオンにします。これにより、memoQはプロジェクト内ですべての翻訳メモリとライブ文書資料を確認します。
-
均一性の計算チェックボックスをオフにします。誰が最初にセグメントを翻訳するかわからないので、memoQは内部あいまい一致をカウントすべきではありません。
詳細については:プロジェクトの均一性と繰り返しのヘルプを参照してください。
- ロックされた行を含めるチェックボックスをオフにします:受け取った文書の一部がロックされているということは、通常、クライアントはあなたにその部分を編集してほしくないということです。
- 繰り返しを100%一致よりも優先チェックボックスにチェックマークが入っていることを確認します:このオプションは、翻訳メモリから一致するものをすべて使用するよりも、一貫した翻訳が重要な場合に使用します。
- クロスファイル繰り返しチェックボックスのチェックマークが外されていることを確認します:誰が繰り返しを使えるかわかりません。
- 加重カウントを表示チェックボックスをオンにします。memoQは、ジョブのおおよその「実際の」単語数を計算します。そのために、memoQはオプションのその他ペインの加重カウントタブにある加重を使用します。
オンラインプロジェクトを管理?オンラインプロジェクトで統計を実行している場合、memoQ serverの加重を使用します。memoQ serverに加重を設定するには、サーバーマネージャを使用します。加重カウントを選択し、加重をチェックまたは設定します。
プロジェクトのサイズを簡単に把握するには、次の設定を使用します。
- プロジェクトの翻訳メモリと資料を使用チェックボックスをオフにします。
- 均一性の計算チェックボックスをオフにします。
- ロックされた行を含めるチェックボックスをオンにします。
- 繰り返しを100%一致よりも優先チェックボックスをオンにします。
- クロスファイル繰り返しチェックボックスをオフにします。
編集者あるいは校正者は、納品された翻訳に対して作業します。その作業は翻訳メモリの一致に頼るわけではありません。テキスト全体で作業するため、翻訳メモリで作業を分析しても意味はありません。
- プロジェクトの翻訳メモリと資料を使用チェックボックスをオフにします。
- 均一性の計算チェックボックスをオフにします。
- 編集者が、新しく翻訳されたセグメントだけでなく、すべての翻訳をレビューする必要がある場合:ロックされた行を含めるチェックボックスをオンにします。
- 繰り返しを100%一致よりも優先チェックボックスをオンにします。
- クロスファイル繰り返しチェックボックスをオフにします。
ほとんどの場合、特に英語から翻訳するときは、作業はソーステキストのワードカウントで測定されます。しかし、一部の市場や対象分野では、翻訳は文字数で測定されます。
結果のテーブルでは、memoQは常に文字数と単語数を表示します。ほとんどの場合、スペースもカウントする必要があります。
文字カウントに空白を含めるチェックボックスにチェックマークが入っていることを確認します。memoQはすべてのスペースを別々にカウントします。スペースが2つ連続する場合は、1つではなく2つのスペースとしてカウントします。
一部の文書形式では、テキストに多数のインラインタグが含まれています。代表的な例は、XML、HTML、PDF、InDesignなどですが、Microsoft Wordなどもこれに当てはまる場合があります。
これらのタグを正しい場所に挿入するのは大変な作業になります。分析レポートには、それが反映されている必要があります。
通常、memoQはタグをカウントしますが、別の番号でカウントします。これを最終的なワードカウントに含めるのは簡単ではありません。
これを設定するために、タグを単語や文字としてカウントすることができます。
タグの加重行の単語数ボックスに数字を入力します。例えば0.25と入力した場合、memoQはインラインタグが4つあるたびに1ワード、つまりタグ1つにつき1/4ワードとカウントします。
これを文字数で数えることもできます。文字数ボックスに数字を入力します。例えば2と入力した場合、memoQはタグ1つにつき2文字とカウントします。
統計ウィンドウには、レポートに含める詳細をmemoQに指示するいくつかのオプションがあります。
- ドキュメントごとにレポートを取得するには:各ファイルの結果を表示(E)チェックボックスをオンにします。
- 分析結果だけでなく、セグメント数、単語数、および文字数の合計を表示するには:カウントを表示(O)チェックボックスをオンにします。通常、memoQはこれを行います。
- ステータスレポートを取得するには - 確定、編集、前翻訳、または未修正のセグメントまたは単語の数:進捗レポート(R)チェックボックスをオンにします。
- 翻訳のサイズを調べるには:ターゲットの数も含める(I)チェックボックスをオンにします。ソースからではなく、ターゲットテキストから請求する場合に使用します。
Trados 2007スタイルのワードカウントを使わないでください:通常、memoQはMicrosoft Wordのように単語を数えます。かつて、Trados 2007以前 (Trados Translator's Workbench) が翻訳ツールとして支配的な立場にあった頃は、翻訳会社が比較できるようにmemoQが同様のワードカウントを生成できることが重要でした。しかし、今はもうこのような状況にありません。Trados 2007スタイルのワードカウントを使うのは、クライアントが過去のバージョンのTradosをかたくなに使い続けている場合のみにしてください。
ソースからではなくターゲット数から請求する?ターゲットの数も含める(I)チェックボックスをオンにします。
上記のすべてのオプションを設定したら、分析を実行できます。計算をクリックします。
プロジェクトのサイズや使用しているリソースによっては、数分またはそれ以上かかる場合があります。
分析が完了すると、統計ウィンドウの下部に結果が表示されます:
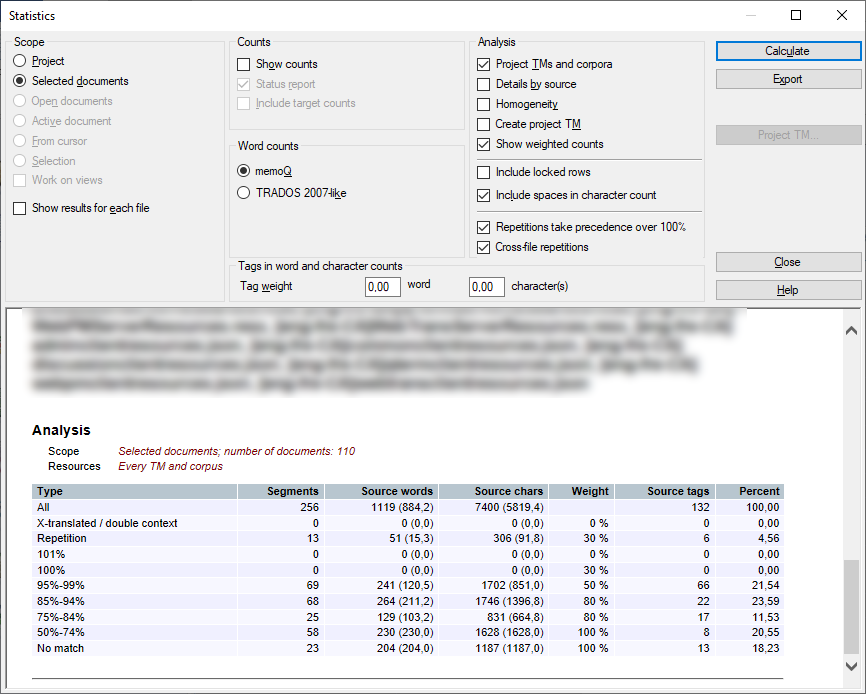
こちらでご覧いただけます。プロジェクトの準備中に、このウィンドウを閉じてプロジェクトに戻ることもできます。たとえば、新しい翻訳メモリを追加して、一致しないカウントを減らすことができます。
または、分析を送信する必要がある場合:ファイルに保存できます。memoQでは、Excelで開くことができるレポートや、Webブラウザで開くことができるレポートを保存できます。
分析結果を保存するには:
- [エクスポート] をクリックします。統計結果のエクスポートウィンドウが開きます。
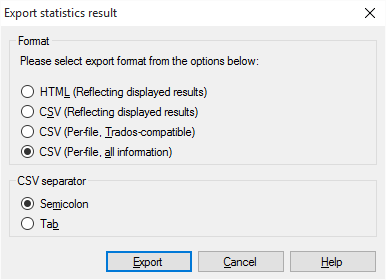
- 次のいずれかの形式を選択します:
- HTML (表示されている結果を反映)(L):表示された統計情報をHTMLファイルとして保存します。
- CSV (表示されている結果を反映)(S):結果をCSVファイルに保存します (Excelで開きます)。
- CSV(ファイル毎、Trados互換)(T):結果をCSVファイルに保存します。各ドキュメントの詳細は正確に1行になります。これは古いTradosスタイルです。
- CSV(ファイル毎、すべての情報)(A):結果をCSVファイルに保存します。結果は統計ウィンドウとまったく同じようにレイアウトされます。
- CSV形式のいずれかを選択した場合は、memoQがテーブル内の列を区切るために使用する区切り文字を選択できます。タブ文字以外を使用する理由はありません:CSV 区切り文字で、タブをクリックします。
- エクスポートをクリックします。形式を選択して保存ウィンドウが開きます。レポートファイルのフォルダと名前を検索し、保存をクリックします。memoQはレポートをエクスポートし、統計ウィンドウに戻ります。
memoQが分析を行う間に、翻訳メモリとプロジェクトのライブ文書資料から関連するセグメントを収集することができます。分析で検出されたセグメントのみを含むプロジェクトTMと呼ばれる特殊な翻訳メモリを作成できます。
そのためには:
- 分析を実行する前に、プロジェクト翻訳メモリを作成チェックボックスをオンにします。
- 分析を実行します:[計算] をクリックします。
- 翻訳メモリを保存します:[プロジェクト TM] をクリックします。プロジェクトTMのエクスポートウィンドウが開きます:
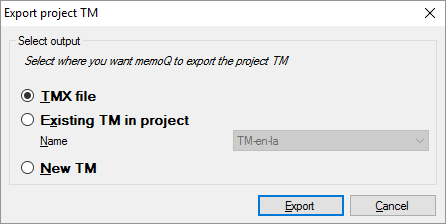
- memoQがセグメントを置く場所を選択します:
- TMXファイルに保存して、別のコンピュータ上の別の翻訳ツールにインポートできます。
- プロジェクトに既に存在する翻訳メモリに保存できます。名前ドロップダウンボックスから、翻訳メモリを選択します。
- または、プロジェクトに新しい翻訳メモリを作成し、そこにセグメントを保存します。
- [エクスポート] をクリックします。memoQはセグメントを保存します。
TMXファイル(T)を選択する場合:形式を選択して保存ウィンドウが開きます。ファイルのフォルダと名前を選択し、保存をクリックします。
結果には、総数セクションと1つまたは複数の分析セクションの2つの部分があります。これは、プロジェクト内の翻訳メモリの数と、各ファイルの結果を表示(E)またはソース単位での詳細チェックボックスの設定によって異なります。
範囲:範囲の選択セクションで選択した分析の範囲です。
リソース:結果が取得されたリソースを示します。ここでは、翻訳メモリ名や均一性のチェックのための均一性が参照できます。集計結果の場合は、すべての翻訳メモリと資料、すべての翻訳メモリと資料または均一性キャプションが表示されます。
種類列:
- すべて:この列には、すべての確定済みのソースセグメント数、ソース単語数、ソース文字数と選択した範囲内のソースワードカウントベースの割合が表示されます。
- クロス翻訳済み:この列には、クロス翻訳済みのソースセグメント数、ソース単語数、ソース文字数と選択した範囲内のソースワードカウントベースの割合が表示されます。
- 繰り返し:この列には、繰り返しのソースセグメント数、ソース単語数、ソース文字数と選択した範囲内のソースワードカウントベースの割合が表示されます。
選択した範囲で分析が実行されます:例えば、プロジェクト内に2つの文書が含まれていて、その両方の文書に同じセグメントが1つ含まれている場合、プロジェクト範囲で計算された統計には、1つのセグメントが繰り返しとして表示されます。2つのドキュメントの統計を別々に計算した場合、結果には繰り返しは表示されません。
大きなプロジェクトを複数の翻訳者に振り分ける場合、この差は重要になります。プロジェクト全体としての統計を取ることで、個々の文書として単独で統計を取るより、繰り返しの率は上がることが考えられるためです。
- 開始前:作業していないソースセグメント、ソース単語およびソース文字の数、および単語数からカウントされたテキストの割合。
- 前翻訳済み:前翻訳されたソースセグメント、ソース単語およびソース文字の数、および単語数からカウントされたテキストの割合。
- フラグメント:フラグメント結合マッチのあるソースセグメント、ソース単語およびソース文字の数、および単語数からカウントされたテキストの割合。
- 編集済み:編集中ソースセグメント、ソース単語およびソース文字の数、および単語数からカウントされたテキストの割合。
- 翻訳者確定済み:確定済みソースセグメント、ソース単語およびソース文字の数、および単語数からカウントされたテキストの割合。
- レビュー担当者 1 確定済み:レビュー担当者1確定済みソースセグメント、ソース単語およびソース文字の数、および単語数からカウントされたテキストの割合。
- レビュー担当者 2 確定済み (校正済み):レビュー担当者2確定済みソースセグメント、ソース単語およびソース文字の数、および単語数からカウントされたテキストの割合。
- ロック済み:ロックされたソースセグメント、ソース単語およびソース文字の数、および単語数からカウントされたテキストの割合。
- パーセンテージ:これらの行には、同じカテゴリに属する一致があるセグメントのソースセグメント数、ソース単語数およびソース文字数、および単語数からカウントされたテキストの割合が表示されます。たとえば、75~84%で5が表示されている場合ですが、リソースがすべての翻訳メモリと資料で範囲がプロジェクトで設定されていると、すべての翻訳メモリの組み合わせから5つのセグメントに対して75~84%の一致が得られることを意味します。
セグメント数列:選択した範囲の、 種類列で指定したソースセグメントの数。
ソースの単語数列:選択した範囲の、種類列で指定したソース単語の数。タグの加重が0でない場合は、実際の単語数よりも大きくなる可能性があります。
ソースの文字数列:選択した範囲の、種類列で指定したソース文字の数。文字数のカウントには、ホワイトスペースは含まれますが、未解釈の書式タグは含まれません。タグの加重が0でない場合は、実際の文字数よりも大きくなる可能性があります。
ソースのタグ列:選択した範囲の、種類列で指定したセグメントにあるタグの数。
割合列:選択した範囲内における、総単語数に対するこのカテゴリのソース単語の割合。丸め誤差があるため、すべての割合の合計は正確には100%になりません。
ターゲットの単語数列:選択した範囲の、種類列で指定したターゲット単語の数。この列は、ターゲットの数も含める(I)チェックボックスがオンになっている場合にのみ表示されます。
ターゲットの文字数列:選択した範囲の、種類列で指定したターゲット文字の数。この列は、ターゲットの数も含める(I)チェックボックスがオンになっている場合にのみ表示されます。
memoQのproject managerエディションでは、1つのプロジェクトに複数のターゲット言語を含めることができます。ローカルプロジェクト、オンラインプロジェクトともです。
プロジェクトのすべてのターゲット言語に対して統計を実行すると、追加の詳細が表示されます。
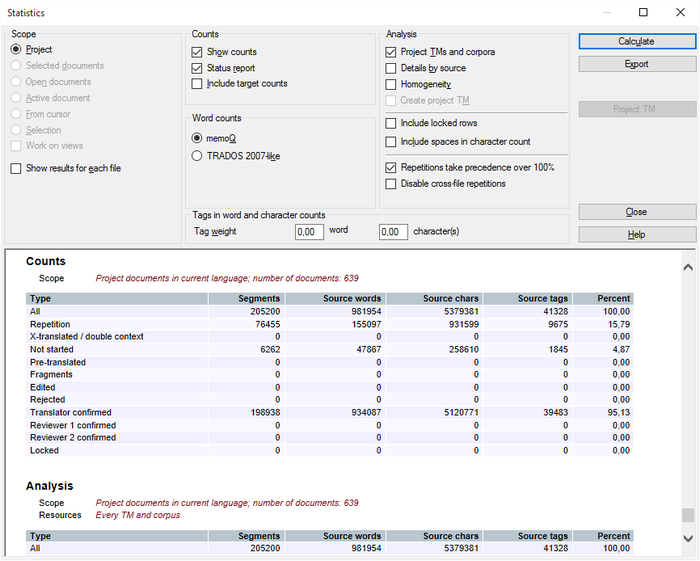
分析をエクスポートするときに、memoQはHTMLとCSV (表示されている結果を反映)オプションでターゲット言語ドキュメントごとに個別の行を追加します。CSV (ファイルごと、Trados 互換)またはCSV (ファイルごと、全情報)でエクスポートする場合、memoQは各ターゲット言語接頭辞が付いたCSVをエクスポートします。例:[ger] sample.txt
注意:ローカルプロジェクトのすべての言語モードで統計を実行する場合、プロジェクトTMを作成するオプションは使用できません。
プロジェクトのソース言語が東アジア言語の場合、memoQは統計結果にソースがアジア言語以外の単語数列とソースがアジア言語の文字数列を追加します:
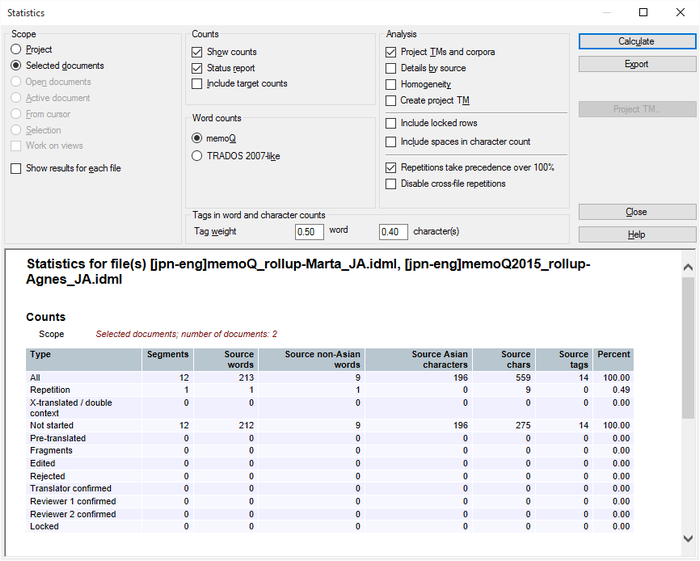
日本語と中国語は、単語を区切るのにスペースを使用しないので、単語数は信頼できません。代わりにアジア文字カウントを使用してください。統計ウィンドウのソースの単語数列には、ソースがアジア言語以外の単語数とソースがアジア言語の文字数 (ソース単語=文字数) の合計が表示されます。
韓国語ではスペースを使用します:韓国語は、日本語や中国語と異なり、単語の区切りにスペースを使用します。韓国語がソース言語である場合は、単語数を使用できます。韓国語はドイツ語等のアルファベット文字をカウントするのと似ています。
完了したら
プロジェクトホーム、memoQ オンラインプロジェクトウィンドウ、または翻訳エディタに戻るには:[閉じる(_C)] をクリックします。