Statistiques
Les statistiques dans memoQ vous aident à estimer la charge de travail et la facturation en analysant le nombre de mots, les correspondances de segments et les répétitions à l’aide de vos mémoires de traduction. Ce guide explique comment exécuter et interpréter les statistiques pour différents rôles du projet et scénarios.
Dans la fenêtre Statistiques, vous pouvez vérifier combien de mots, segments ou caractères se trouvent dans votre projet ou documents sélectionnés. memoQ compare également ceux-ci avec vos mémoires de traduction et bases LiveDocs pour montrer combien de contenu a déjà été traduit ou peut être recyclé.
-
Vous pouvez automatiser cela : dans un projet créé à partir d’un modèle de projet,memoQ peut créer un rapport d’analyse automatiquement.
-
Utilisez la fenêtre Statistiques lorsque vous avez besoin de plus de paramètres : dans l’aperçu d’un projet local ou dans le volet Rapports d’un projet en ligne, vous pouvez rapidement créer des rapports d’analyse sur l’ensemble du projet, avec moins de paramètres.
-
Pour déterminer combien de travail est nécessaire, en tenant compte des correspondances dans vos mémoires de traduction et bases LiveDocs.
-
Analyser à la fois les projets locaux et les projets en ligne avec des paramètres personnalisés.
-
Pour estimer votre facturation en fonction des comptes de mots pondérés.
memoQ mots des groupes par catégorie de correspondance (correspondances exactes, 95-99 %, etc.). Chaque catégorie a un poids représentant combien de travail est nécessaire (0 % = aucun travail, 100 % = traduction complète).
Par exemple: Un segment de correspondance de 90 % avec 10 mots et 50 % de poids compte comme 5 mots de travail.
Comment se rendre ici
-
Ouvrez un document pour traduction - si vous voulez analyser une partie de celui-ci.
-
Dans l’onglet Documents, cliquez sur Statistiques.
-
La fenêtre Statistiques s’ouvre.
Vous pouvez gérer des projets en ligne seulement si vous êtes membre des Chefs de projet ou du groupe Administrateurs sur le memoQ TMS – ou si vous avez le rôle de chef de projet dans le projet.
-
Dans la fenêtre du projet en ligne memoQ, cliquez sur Traductions.
-
Dans l’ onglet Préparation du ruban, cliquez sur Statistiques.
La fenêtre Statistiques s’ouvre.
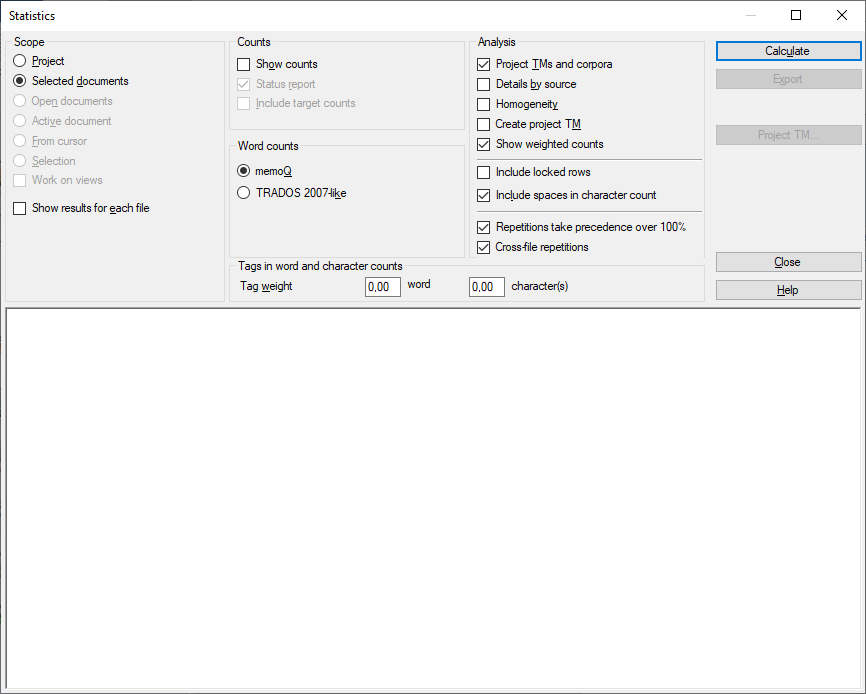
Que pouvez-vous faire?
Une étendue indique à memoQ quels documents examiner.
-
Projet : Tous les segments dans tous les documents du projet actuel. Si le projet a deux langues cibles ou plus, memoQ vérifiera les segments dans chaque langue cible.
-
Document actif: Tous les segments dans le document actif. Vous pouvez choisir cela seulement si vous travaillez sur un document dans l’éditeur de traduction.
-
Documents sélectionnés: Tous les segments dans les documents sélectionnés. Vous pouvez choisir cela seulement si vous sélectionnez plusieurs documents dans Traductions sous l'Accueil.
-
Depuis le curseur: Les segments sous la position actuelle dans le document actif. Vous pouvez choisir cela seulement si vous travaillez sur un document dans l’éditeur de traduction.
-
Documents ouverts: Tous les segments dans chaque document qui est ouvert dans un onglet de l’éditeur de traduction.
-
Sélection: Segments sélectionnés dans le document actif. Vous pouvez choisir cela seulement si vous travaillez sur un document dans l’éditeur de traduction.
-
Travailler sur les vues : Segments dans les vues du projet en cours. Vous pouvez choisir cette option seulement s’il y a au moins une vue dans le projet.
Analyser des segments dans une seule langue cible: Avant d’ouvrir la fenêtre Statistiques, choisissez une langue dans le volet Traductions. Sélectionnez tous les documents, puis ouvrez les statistiques et choisissez les documents sélectionnés.
Ces paramètres sont pour un projet local.
Lorsque vous exécutez des statistiques par vous-même, utilisez ces paramètres dans la fenêtre Créer un rapport d’analyse:
-
Utilisez les MT de projet et les bases LiveDocs pour trouver des correspondances. memoQ vérifie les segments dans chaque mémoire de traduction et base LiveDocs de votre projet.
-
Utilisez l’homogénéité pour compter correctement les segments répétés. memoQ prédit quels correspondances vous obtiendrez lors de la traduction pendant que votre mémoire de traduction se remplit. Il est logique d’utiliser cette option seulement si vous travaillez sur la traduction seul.
-
Effacer l’inclusion des segments verrouillés s’il y en a (ce sont des segments que vous ne devriez pas traduire).
-
Choisissez les répétitions qui ont la priorité sur 100 % afin que les segments répétés ne soient pas comptés deux fois. Utilisez-le seulement si une traduction cohérente est plus importante que l’utilisation de toutes les correspondances possibles de la mémoire de traduction.
-
Assurez-vous d’utiliser les répétitions inter-fichiers si votre projet comporte plusieurs documents, afin que les répétitions entre les fichiers soient reconnues.
-
Sélectionnez Afficher les comptes pondérés pour voir l’estimation de l’effort réel.
Gestion d’un projet en ligne?
Si vous exécutez des statistiques sur un projet en ligne,memoQ utilise les pondérations du memoQ TMS.
Pour définir des pondérations sur un memoQ TMS, utilisez l’ Administrateur de serveur . Choisissez des comptes pondérés et vérifiez ou définissez les poids.
Ces paramètres sont pour un projet en ligne. Utilisez-les également dans un projet local, si vous êtes chef de projet, et que vous prévoyez de publier le projet sur un serveur, ou de distribuer le projet en utilisant des packages de traduction.
Si plusieurs traducteurs travailleront sur le projet, utilisez ces paramètres dans la fenêtre Créer un rapport d’analyse:
-
Utilisez les MT et les bases LiveDocs du projet pour trouver des correspondances. memoQ vérifie les segments dans chaque mémoire de traduction et base LiveDocs du projet.
-
Ne calculez pas l ’Homogénéité . Vous ne pouvez pas prédire les correspondances partielles internes parce que vous ne savez pas qui traduit un segment en premier.
-
Ne sélectionnez pas Inclure les segments verrouillés à moins que les traducteurs ne travaillent sur du contenu verrouillé.
-
Choisissez les répétitions qui ont la priorité sur 100 % afin que les segments répétés ne soient pas comptés deux fois. Utilisez-le seulement si une traduction cohérente est plus importante que l’utilisation de toutes les correspondances possibles de la mémoire de traduction.
-
Effacer les répétitions inter-fichiers parce que nous ne savons pas qui traduira un segment en premier - et ils devraient recevoir une pleine compensation pour la traduction.
-
Sélectionnez Afficher les comptes pondérés pour voir des estimations de travail réalistes.
Pour découvrir combien de travail une équipe de traducteurs a effectué, utilisez l’ analyse post-traduction après que la traduction soit terminée.
Si vous exécutez des statistiques sur un projet en ligne, memoQ utilisera les pondérations du memoQ TMS.
Pour définir des pondérations sur un memoQ TMS, utilisez l’ Administrateur de serveur . Choisissez des comptes pondérés et vérifiez ou définissez les poids.
Pour obtenir un nombre simple de la taille totale du texte sans analyse de correspondance :
-
Décochez les cases Utiliser les TMS et bases LiveDocs du projet, Homogénéité et Répétitions entre fichiers.
-
Sélectionnez Inclure les segments verrouillés et les répétitions ont priorité sur 100 %.
Les éditeurs (insérioriser) travaillent sur du contenu déjà traduit, peu importe les correspondances, donc il n’est pas logique d’analyser le travail à travers les mémoires de traduction.
-
Décochez les cases Utiliser les TMS et bases LiveDocs du projet, Homogénéité et Répétitions entre fichiers.
-
Vérifiez que les répétitions ont la priorité sur 100 %, et si l’éditeur examine le contenu verrouillé, vérifiez Inclure les segments verrouillés.
Certains marchés mesurent le volume de traduction par caractères au lieu de mots. memoQ affiche toujours le nombre de caractères à côté du nombre de mots.
Pour compter les espaces, assurez-vous que l’option Inclure les espaces dans le nombre de caractères est sélectionnée. memoQ compte chaque espace séparément, par exemple, deux espaces l’un après l’autre comptent comme deux, et non comme un.
Les formats comme XML,HTML,PDF,InDesign ou Microsoft Word incluent souvent de nombreuses balises internes, ce qui ajoute à la complexité d’édition. Le rapport d’analyse doit en tenir compte.
Vous pouvez attribuer des pondérations aux balises :
-
Définir le poids des balises en mots ou en caractères
Dans le champ poids des balises, tapez un nombre dans la boîte de mot(s) ou caractère(s) (par exemple, 0,25 mot par balise ou 2 caractère(s) par balise).
Si vous tapez 0.25,memoQ compte un mot après chaque quatre balises internes, ou, si vous tapez 2,memoQ compte deux caractères après chaque balise.
-
memoQ ajoute ensuite ces comptes pondérés à votre estimation totale de charge de travail.
Dans la fenêtre Statistiques, il y a plusieurs options qui indiquent à quels détails inclure dans le rapport.
-
Afficher les résultats pour chaque fichier génère un rapport séparément pour chaque document.
-
Afficher les décomptes montre le nombre total pour les segments, mots et caractères.
-
Le rapport d’état montre les états des segments (confirmés, édités, prétraduits, non commencés).
-
Inclure les comptes cibles est nécessaire si vous facturez en fonction de la taille du texte cible.
Après avoir réglé vos options, cliquez sur Calculer. Le processus peut prendre plusieurs minutes selon la taille du projet.
Lorsque l’analyse est terminée memoQ l’affiche au bas de la fenêtre des statistiques:
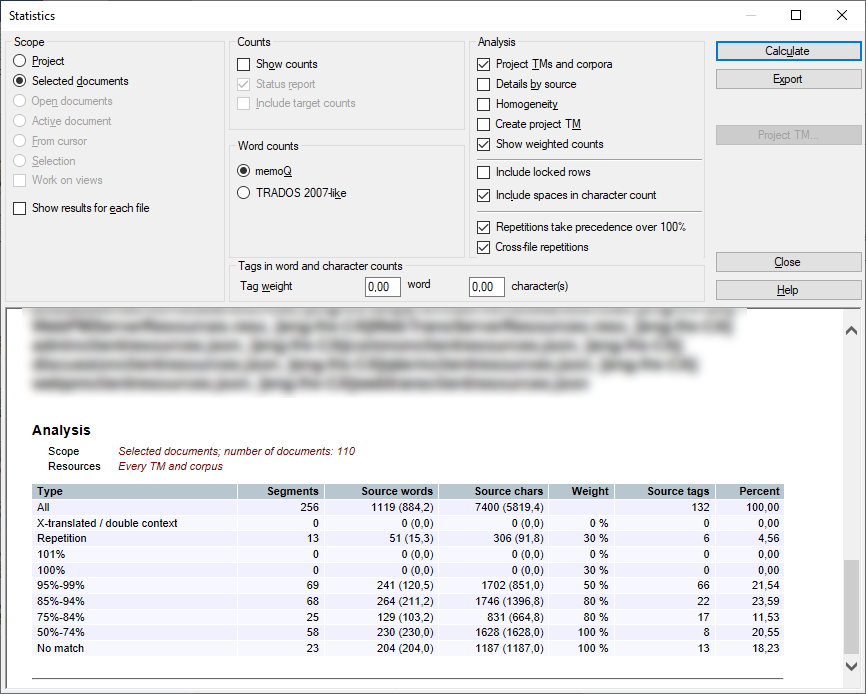
Vous pouvez le consulter ici ou exporter des rapports dans plusieurs formats.
Exporter et sauvegarder le rapport d’analyse :
-
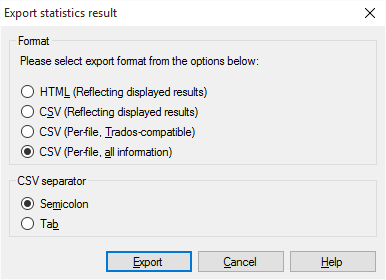
Cliquez sur Exporter. La fenêtre Exporter les statistiques s’ouvre.
-
Choisissez un des formats:
- HTML (reprenant les résultats affichés): Sauvegarde les statistiques affichées en tant que fichier HTML.
- CSV (reprenant les résultats affichés): Sauvegarder les résultats dans un fichier CSV (à ouvrir dans Excel).
- CSV (par fichier, compatible TRADOS): Sauvegarde les résultats dans un fichier CSV, où les détails de chaque document occupent exactement un segment. C’est l’ancien style Trados.
- CSV (par fichier, toutes les informations): Sauvegarder les résultats dans un fichier CSV, où les résultats sont disposés exactement comme dans la fenêtre des statistiques.
-
Si vous choisissez l’un des formats CSV, vous pouvez choisir le caractère de séparateur que memoQ utilise pour délimiter les colonnes dans la table. Il n’y a aucune raison d’utiliser autre chose que le caractère de tabulation: Sous le séparateur CSV, cliquez sur Tab.
-
Cliquez sur Exporter. Une fenêtre Enregistrer sous s’ouvre. Trouvez un dossier et un nom pour le fichier de rapport, puis cliquez sur Enregistrer. memoQ exporte le rapport et revient à la fenêtre des statistiques.
memoQ peut collecter tous les segments des mémoires de traduction et des bases LiveDocs trouvés lors de l’analyse dans un MT de projet spécial pour une réutilisation plus facile.
Pour cela :
-
Avant de lancer l’analyse, cochez la case Créer la MT du projet.
-
Exécuter l’analyse: Cliquez sur Calculer.
-
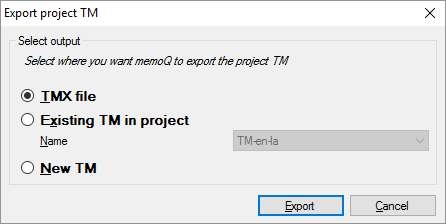
Sauvegarder la mémoire de traduction: Cliquer sur le projet MT. La fenêtre Exporter le projet MT s’ouvre:
-
Choisissez où memoQ devrait mettre les segments :
- Vous pouvez les enregistrer dans un fichier TMX, afin qu’il puisse être importé sur un autre ordinateur, dans un autre outil de traduction.
- Vous pouvez les enregistrer dans une mémoire de traduction qui est déjà dans votre projet. Dans la zone déroulante Nom, choisissez la mémoire de traduction.
- Ou, vous pouvez créer une nouvelle mémoire de traduction dans le projet et y enregistrer les segments.
-
Cliquez sur Exporter. memoQ enregistre les segments.
Les résultats sont divisés en deux sections principales :
-
Les décomptes — montre le total de segments, mots, caractères.
-
Analyse — répartition détaillée par type de match et ressource (MT, homogénéité, etc.).
Vous pouvez avoir plus d’une sections d’analyse. Cela dépend du nombre de mémoires de traduction dans votre projet, ainsi que des paramètres dans les cases à cocher Afficher les résultats pour chaque fichier ou Détails par source.
Étendue de l’analyse sélectionnée dans la section Sélectionner l’étendue.
Ressources - les ressources contre lesquelles les résultats ont été obtenus. Ici, vous trouvez le nom d’une mémoire de traduction ou "homogénéité" pour les contrôles d’homogénéité. Si ce sont des résultats agrégés, vous voyez la légende Chaque MT et base LiveDocs ou Chaque MT et base LiveDocs, Homogénéité.
Vous verrez des segments pour :
-
Tous - étendue entière (tous les segments source, mots sources, caractères, et le pourcentage de mots source).
-
Prétraduire depuis une version antérieure - segments source traduits, mots sources, caractères, et le pourcentage de mots source.
-
Répétition- segments répétés (tous les segments source, mots sources, caractères, et le pourcentage de mots source).
-
Plages de correspondance par pourcentage (par exemple, 95-99 %).
-
Comptes de segments, comptes de mots et de nombres de caractères source et cible.
Travaux d’analyse pour l’étendue sélectionnée. Par exemple, si vous avez deux documents dans votre projet, et que les deux contiennent le même segment une seule fois, les statistiques calculées pour l’étendue du projet montreront un segment comme répétition. Si vous calculez les statistiques séparément pour les deux documents, les résultats ne montreront aucune répétition.
Cette différence peut être significative si vous prévoyez de diviser un grand projet entre différents traducteurs, car les statistiques globales pour le projet complet peuvent montrer un taux de répétitions beaucoup plus élevé que les différents ensembles de documents.
-
Non commencé : Nombre de segments, mots et caractères sources intacts, ainsi que le pourcentage du texte compté à partir du nombre de mots.
-
Prétraduit : Nombre de segments, mots et caractères sources prétraduits ainsi que le pourcentage du texte compté à partir du nombre de mots.
-
Fragments: Nombre de segments, mots et caractères sources ainsi que le pourcentage du texte compté à partir du nombre de mots, où il y a des correspondances issues d’un assemblage de fragments.
-
Édité : Nombre de segments, mots et caractères sources édités ainsi que le pourcentage du texte compté à partir du nombre de mots.
-
Confirmé par Traducteur : Nombre de segments, mots et caractères sources confirmés ainsi que le pourcentage du texte compté à partir du nombre de mots.
-
Confirmé par Relecteur 1 : Nombre de segments, mots et caractères sources confirmés par Relecteur 1 ainsi que le pourcentage du texte compté à partir du nombre de mots.
-
Confirmés par Relecteur 2 (presque) : Nombre de segments source du relecteur 2, mots source, caractères, et le pourcentage du texte compté à partir du nombre de mots.
-
Verrouillé : Nombre de segments, mots et caractères sources verrouillés ainsi que le pourcentage du texte compté à partir du nombre de mots.
-
Plages de pourcentage: Ces segments montrent le nombre de segments, mots et caractères sources ainsi que le pourcentage du texte compté à partir du nombre de mots, pour les segments qui ont une correspondance dans la même catégorie.
Par exemple, si vous voyez 5 après 75 à 84% des correspondances, lorsque la ressource est chaque MT et base LiveDocs, et que l’étendue est Projet, cela signifie que la combinaison de toutes les mémoires de traduction donnera 75 à 84% des correspondances pour cinq segments.
Colonnes dans le rapport d’analyse :
Chaque segment (chaque type) a une valeur dans ces segments :
-
Segments: Nombre de segments sources de ce type dans l’étendue sélectionnée.
-
Mots sources : Nombre de mots sources de ce type dans l’étendue sélectionnée. Si le poids de la balise n’est pas 0, cela peut être supérieur au nombre de mots réel.
-
Caractères sources : Nombre de caractères sources de ce type dans l’étendue sélectionnée. Les nombres de caractères incluent les espaces vides mais n’incluent pas les balises de formatage non interprétées. Si le poids de la balise n’est pas 0, cela peut être supérieur au nombre de caractères réel.
-
Balises sources : Nombre de balises incluses dans les segments spécifiés par la colonne Type, dans l’étendue sélectionnée.
-
Pourcentage: Pourcentage des mots sources dans cette catégorie par rapport au nombre total de mots, dans l’étendue sélectionnée. La somme de tous les pourcentages peut ne pas être précisément de 100% en raison des marges d’arrondi.
-
Mots cibles : Nombre de mots cibles de ce type dans l’étendue sélectionnée. Cette colonne apparaît uniquement si la case Inclure les comptes cibles est cochée.
-
Caractères cibles : Nombre de caractères cibles de ce type dans l’étendue sélectionnée. Cette colonne apparaît uniquement si la case Inclure les comptes cibles est cochée.
Lorsque vous exécutez des statistiques pour toutes les langues cibles du projet, vous obtiendrez des détails supplémentaires:
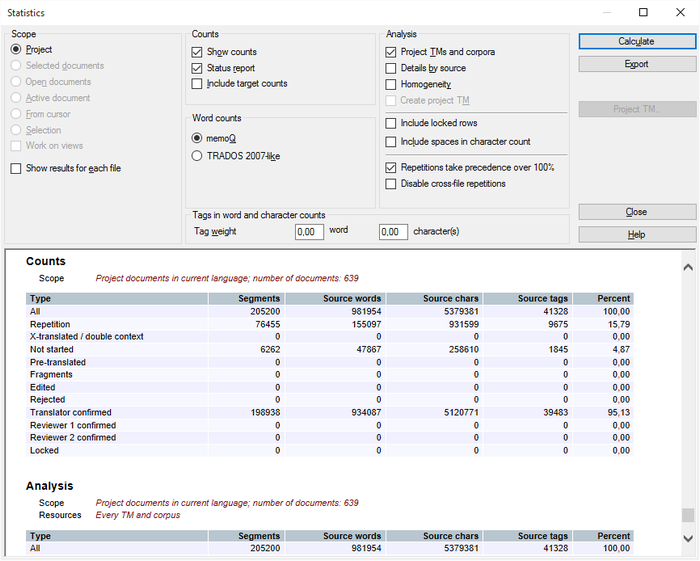
Lorsque vous exportez l’analyse memoQ ajoute maintenant un segment séparé pour chaque document de langue cible pour les options HTML et CSV (réflétant les résultats affichés ). Si vous choisissez d’exporter au format CSV (par fichier, Trados-compatible) ou CSV (par fichier, toutes les informations ), memoQ exportera un fichier CSV avec un préfixe pour chaque langue cible, par exemple [ger] sample.txt:
Pour les langues sources comme le japonais ou le chinois (sans espaces entre les mots), memoQ ajoute des mots sources non asiatiques et des colonnes de caractères asiatiques sources aux résultats des statistiques.
memoQ montres :
-
Compte de mots sources non asiatiques au lieu de compte de mots.
-
La colonne combinée des Mots sources comprend des caractères asiatiques ainsi que des mots non asiatiques.
Le coréen utilise des espaces, donc le compte de mots fonctionne de manière similaire aux langues européennes.